Trading Signals with Adaptive SuperTrend and K-Means
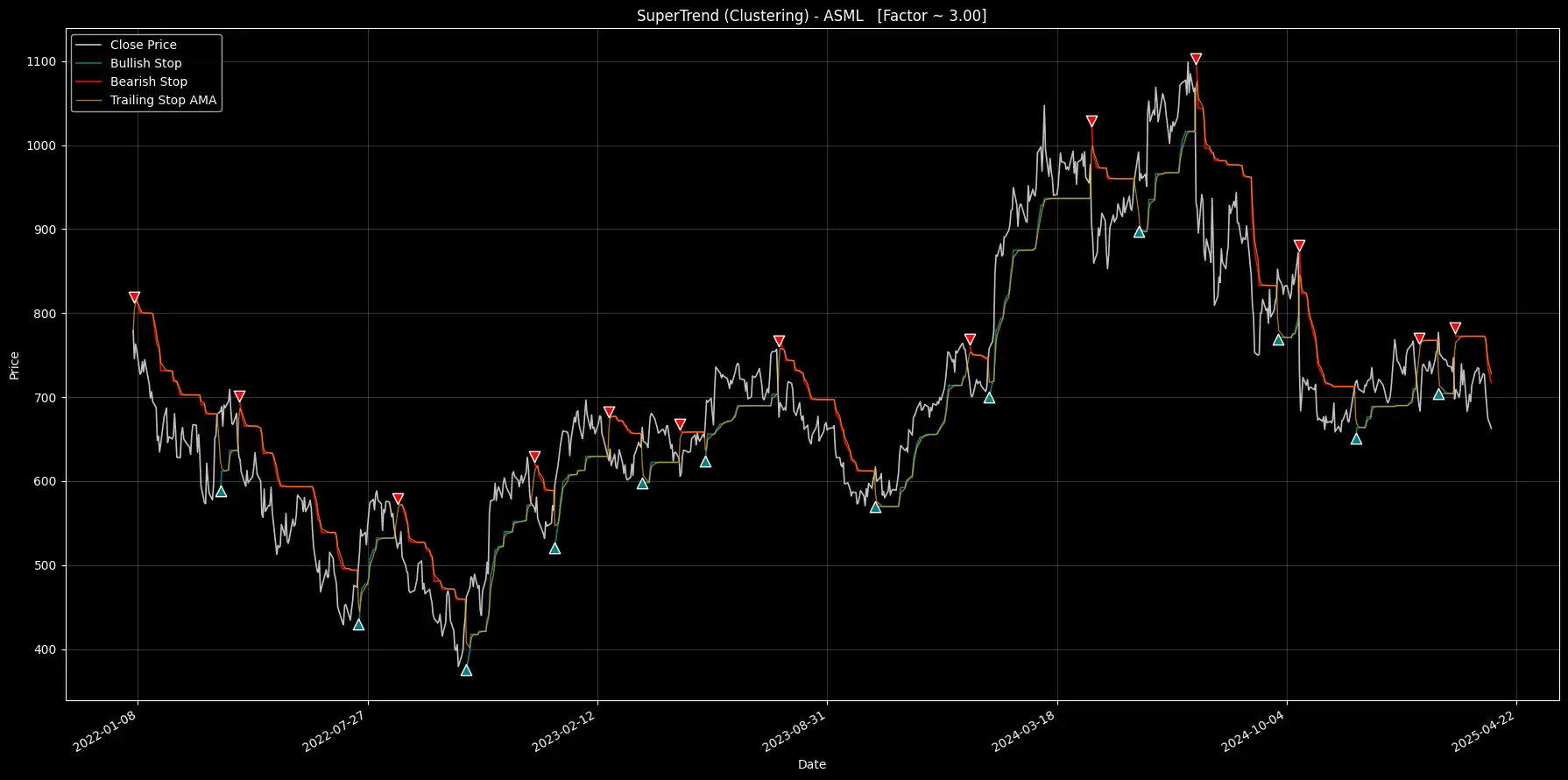

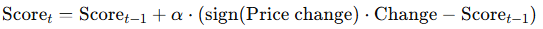

Figure 1. Architecture Diagram: Trading Signals with Adaptive SuperTrend and K-Means Clustering




Newsletter
Get Every Weekly Update & Insights
[mc4wp_form id=]
One thought on “Trading Signals with Adaptive SuperTrend and K-Means”
will you help me to implement it