Pattern Mining for Stock Prediction with Dynamic Time Warping

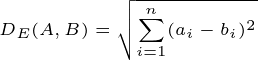

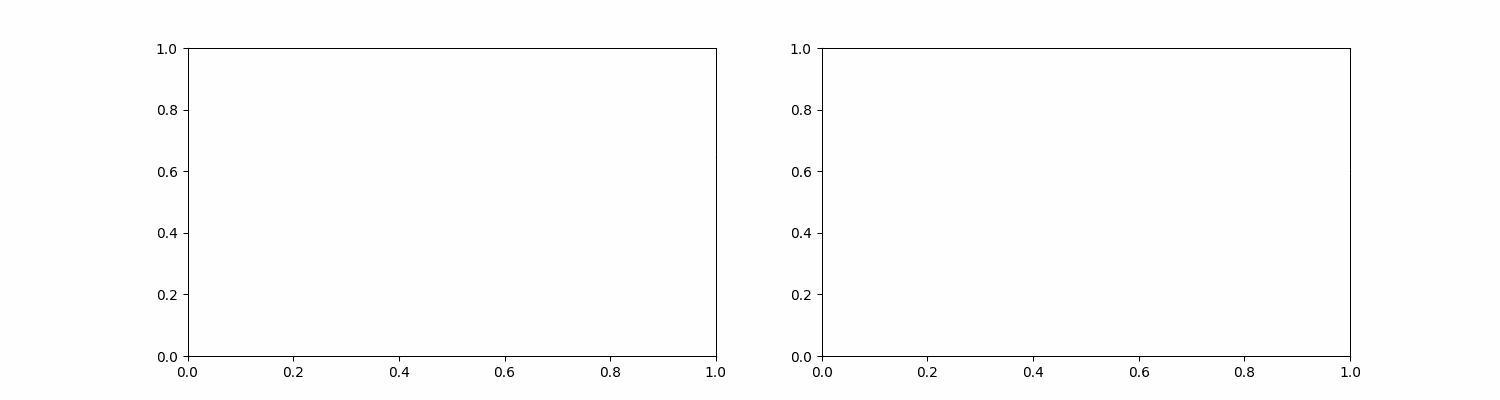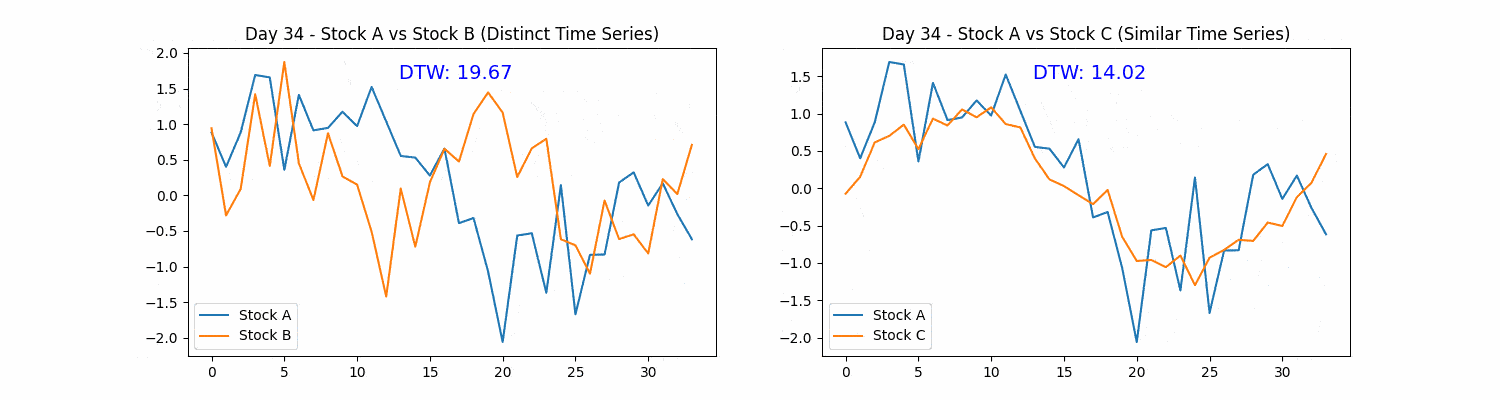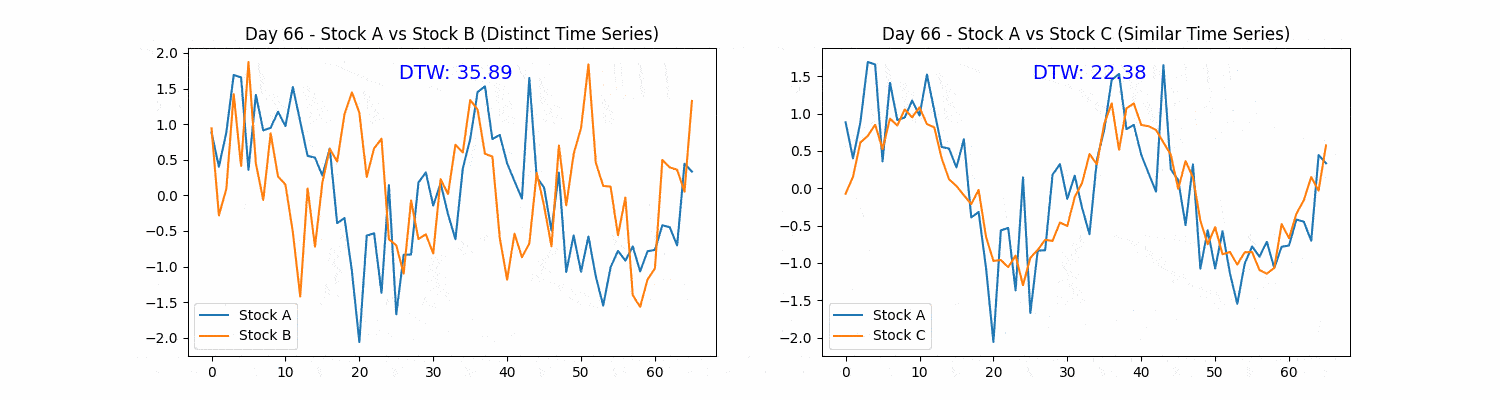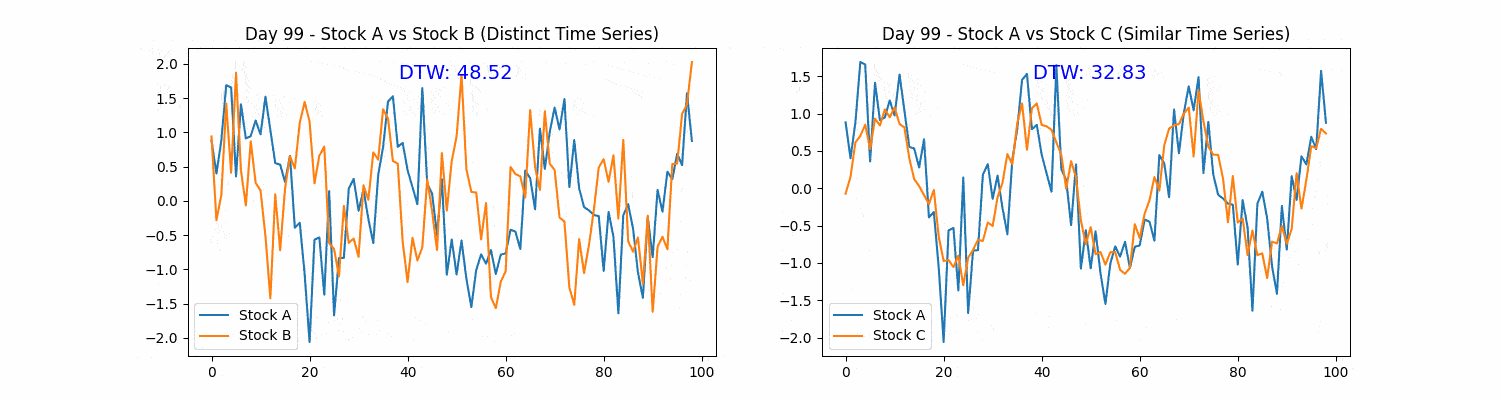
Figure. 1: Dynamic Time Warping (DTW) in Stock Analysis: The animation demonstrates two scenarios of stock price patterns, revealing divergent and parallel trends in the left and right subplots respectively. DTW distances quantify the temporal similarity between the evolving patterns, with lower DTW values indicating higher similarity, providing insights into the adaptability and precision of DTW in identifying similarities amidst temporal displacements in financial data.

Newsletter
Get Every Weekly Update & Insights
[mc4wp_form id=]
One thought on “Pattern Mining for Stock Prediction with Dynamic Time Warping”