Extracting Future Price Expectations from Options
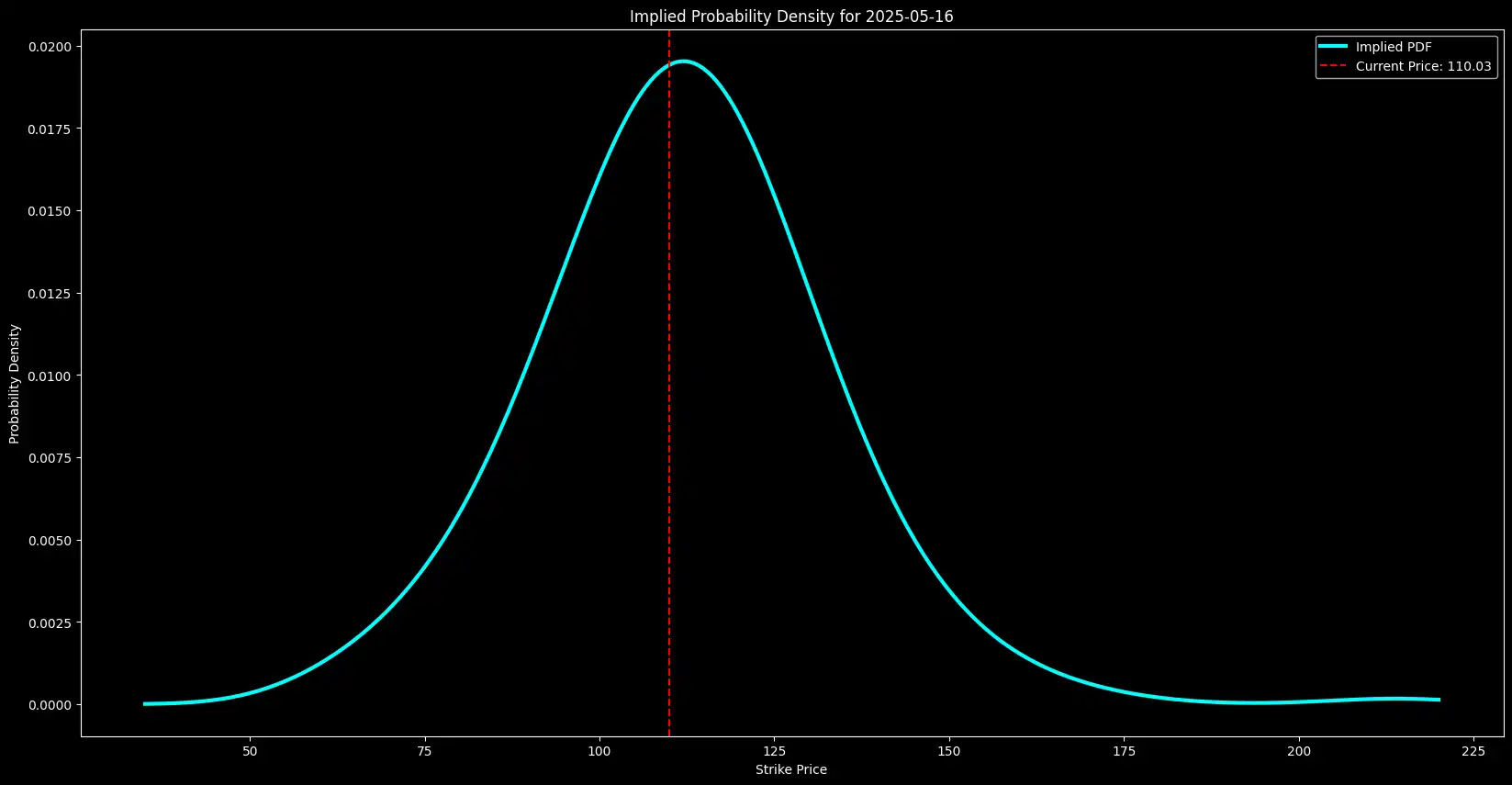
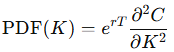
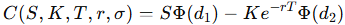
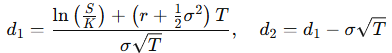
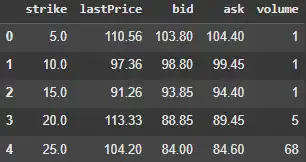
Figure 1. Raw option chain data before filtering. It shows strike prices, last traded prices, bid-ask quotes, and volume.
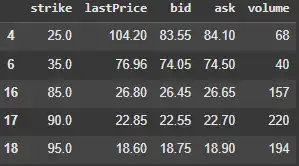
Figure 2. Filtered option chain data after removing illiquid contracts. It excludes options with low volume and wide bid-ask spreads.

Newsletter
Get Every Weekly Update & Insights
[mc4wp_form id=]