Uniting LLMs with Knowledge Graphs for Fact-Based Chatbots
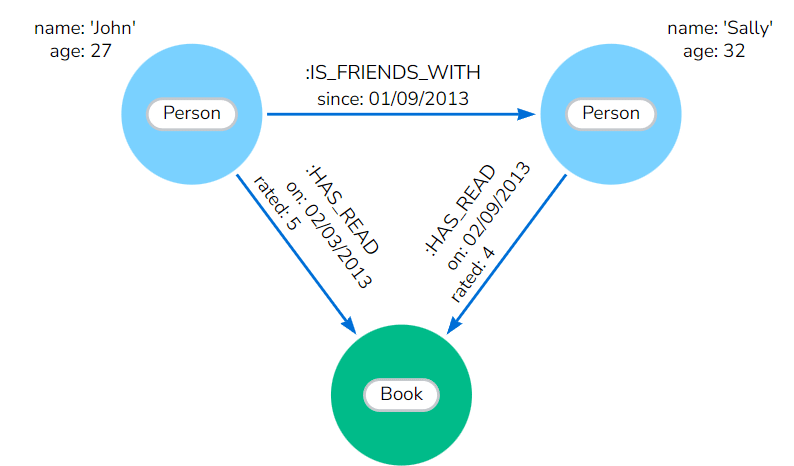
Figure. 1: Graph Model Example: Nodes and Relationships in a Neo4j Knowledge Graph" - illustrating the connections between entities 'John' and 'Sally', and their interaction with a 'Book' (Source: Neo4j)
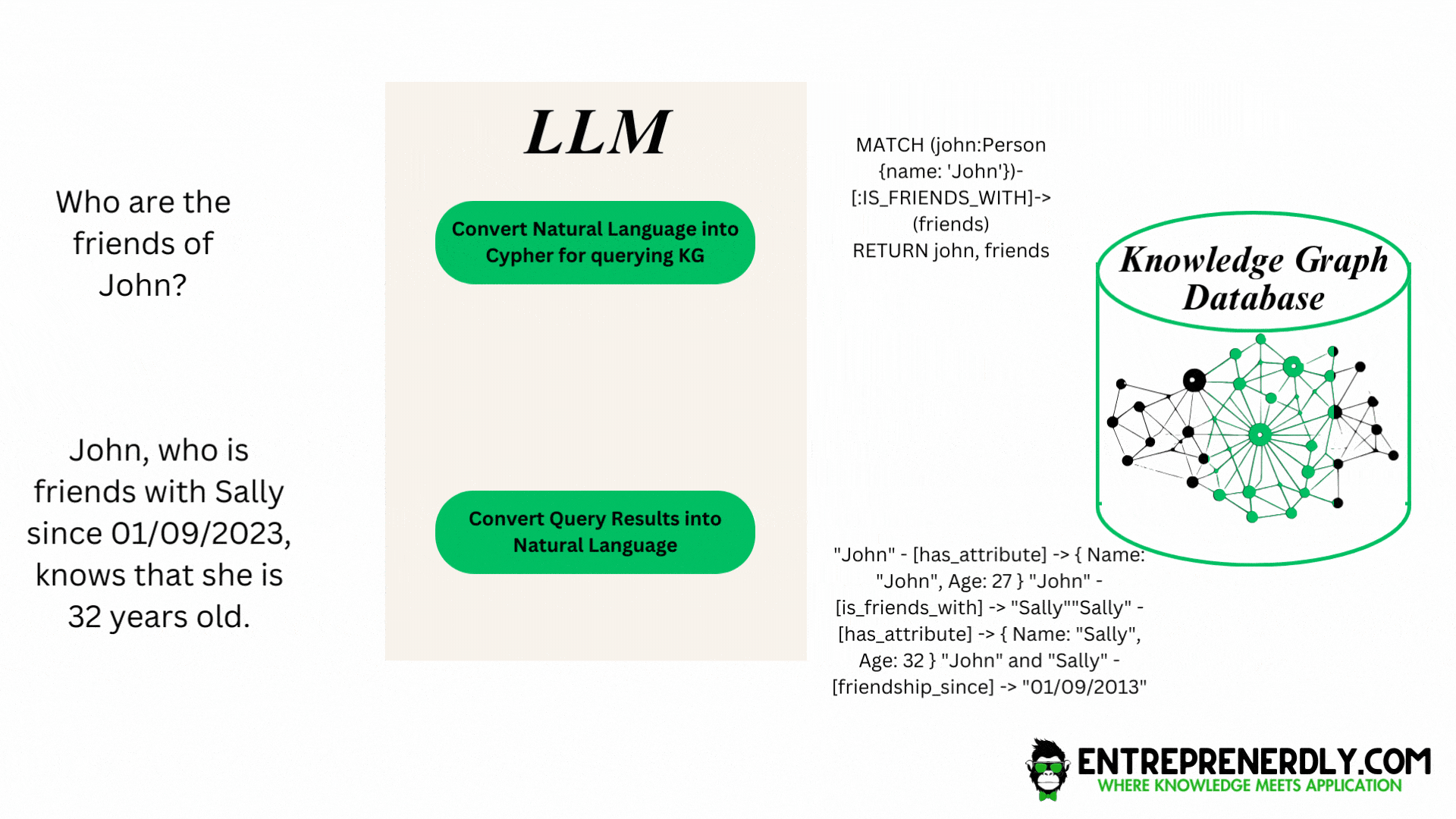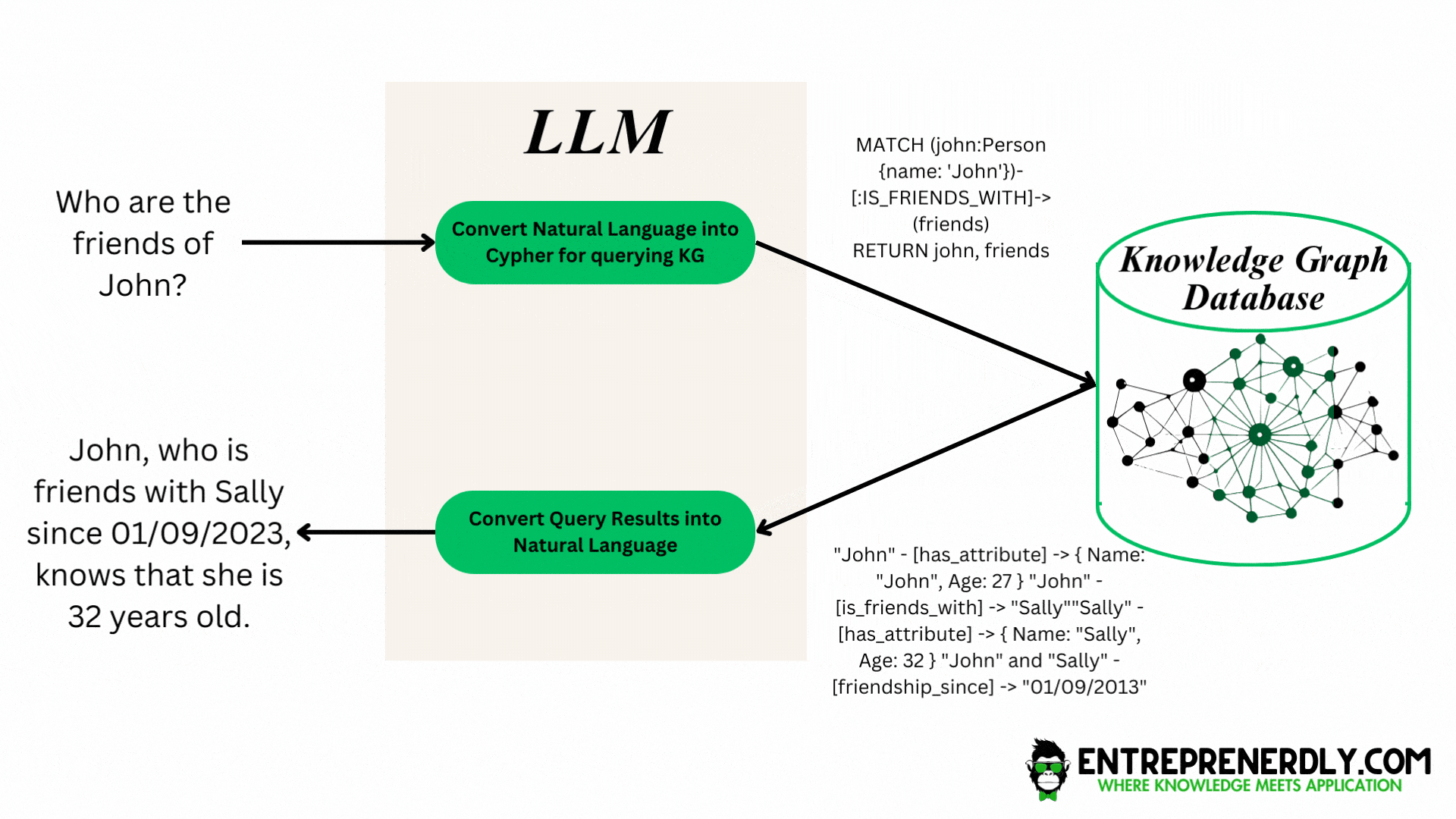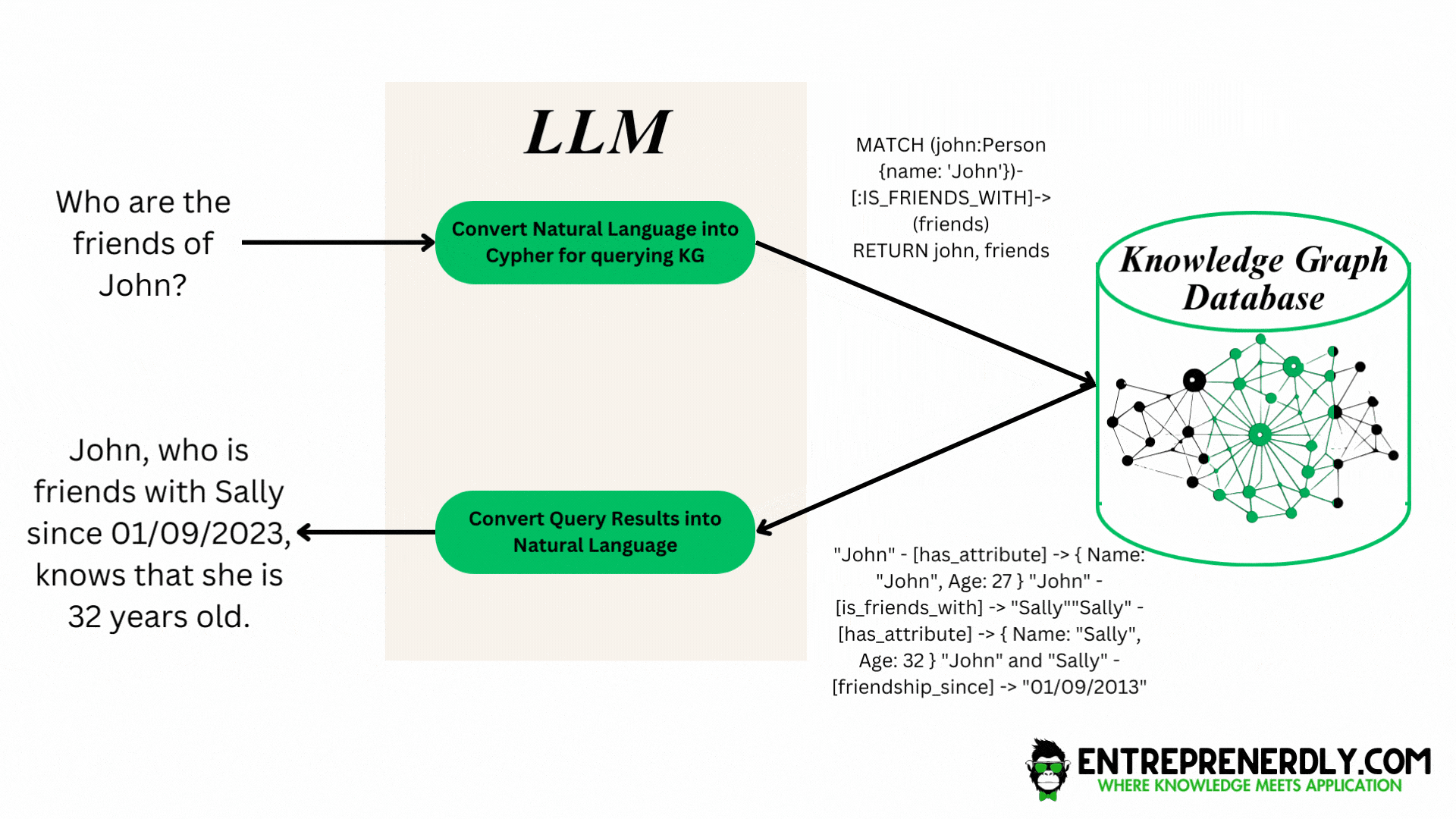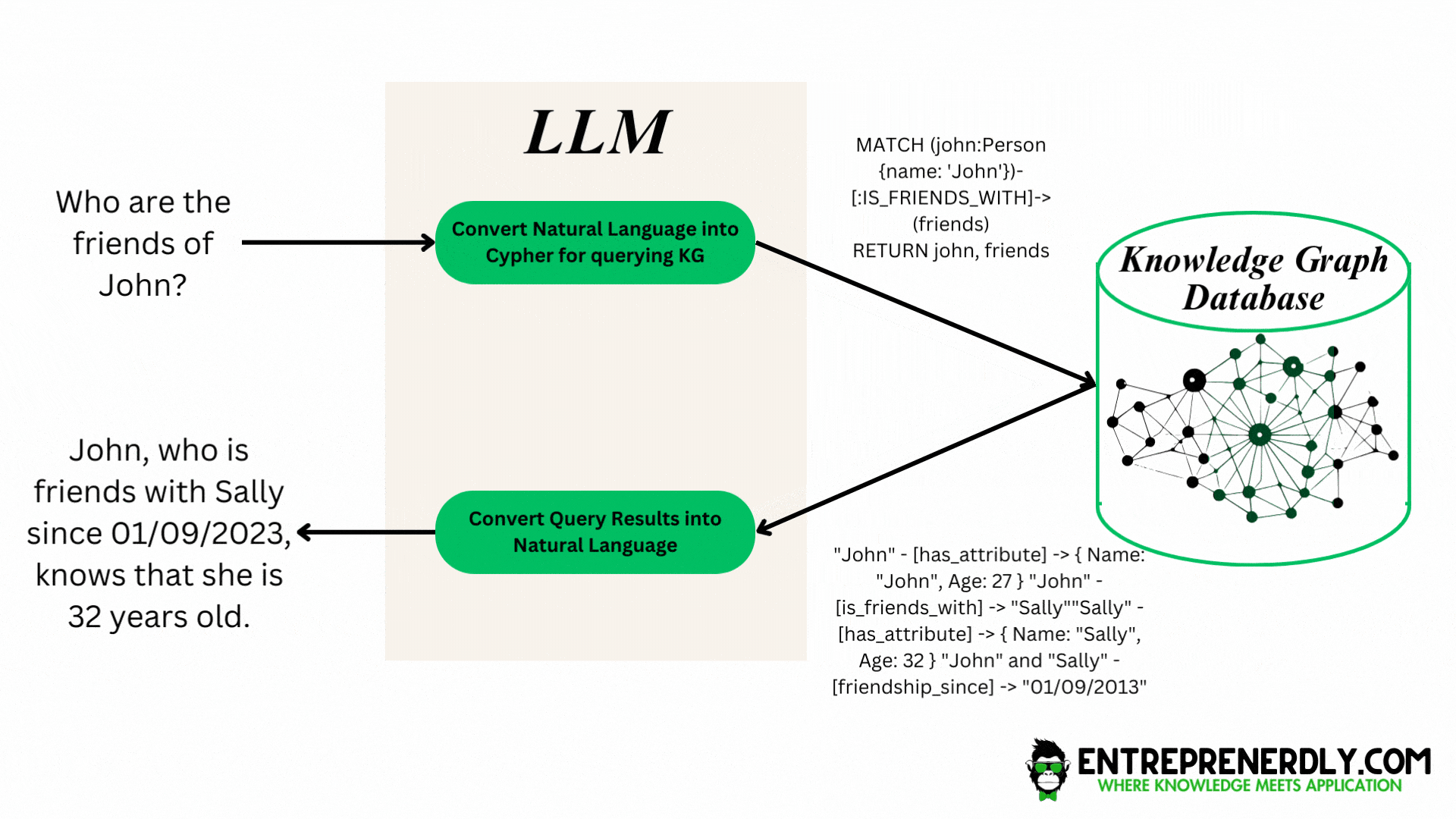
Figure. 2: This diagram illustrates how a user's natural language question is interpreted by an LLM and converted into a structured graph database query, which in turn results in a clear, informative response from the knowledge graph.

Figure. 3: LLM-Enhanced ETL Process: This diagram depicts the role of a fine-tuned LLM in orchestrating an ETL pipeline, from extracting entities and relationships from raw data to structuring them into a knowledge graph.
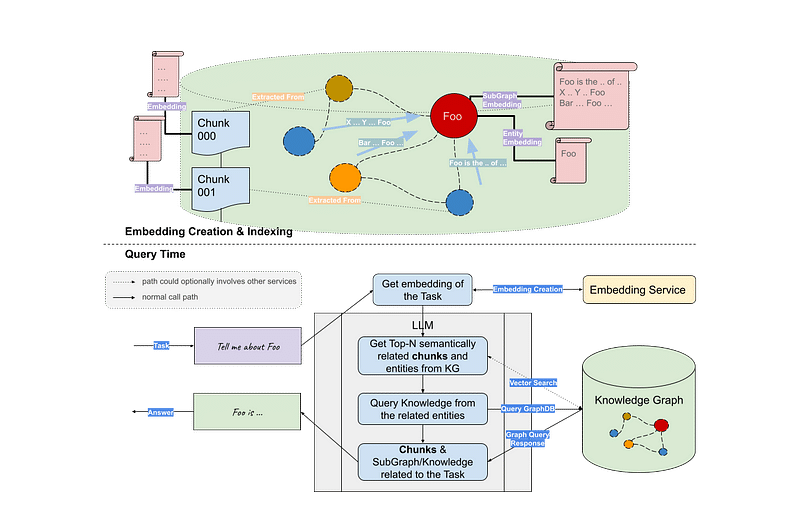
Figure. 4: Integrating LLMs with Knowledge Graphs for Enhanced Query Processing: This flowchart illustrates the process of embedding natural language tasks, retrieving and constructing knowledge subgraphs, and generating context-rich answers (Source: Llama-index)

Figure. 5: Comparison of 'Free' and 'Professional' service tiers for Neo4j Aura, illustrating options for different user needs.

Figure. 6: A display of Neo4j Aura database password provided upon instance creation.
Figure. 7: A view of an active Neo4j Aura instance, showing its status and connectivity details.

Newsletter