Advances in 3D Scene Mapping and Object Modeling from Meta, Google, and Stability AI
The field of 3D reconstruction, which aims to create digital 3D models from 2D data like images or videos, is rapidly evolving. Three cutting-edge approaches from tech giants Meta, Google, and Stability AI have been recently announced.
Meta’s SceneScript uses large language models to generate compact, interpretable text descriptions that represent the geometry and layout of physical spaces. Trained entirely in simulation, SceneScript overcomes privacy challenges while showing promise for augmented reality and virtual assistants.
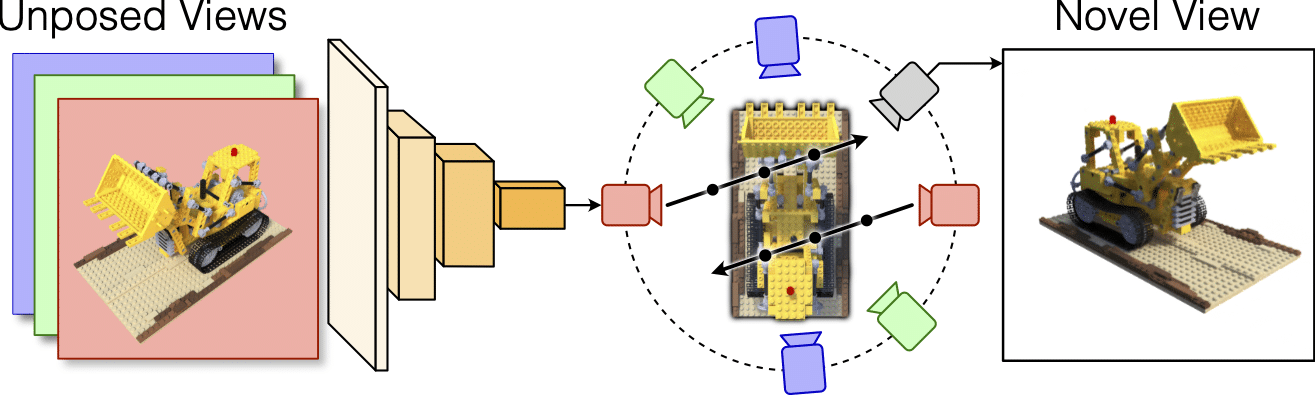
Google’s MELON tackles the complex “chicken and egg” problem of reconstructing 3D objects from just a few unposed 2D images without any initial pose estimates. By leveraging lightweight neural networks and a novel modulo loss, MELON achieves state-of-the-art results on standard benchmarks.
Stability AI’s Stable Video 3D builds upon their video diffusion models to generate high-quality, consistent multi-view videos of 3D objects from just a single image. These videos enable optimizing Neural Radiance Fields for generating detailed 3D meshes, advancing applications like digital twins and AR/VR experiences.
Meta’s SceneScript
SceneScript is a novel approach developed by Meta’s Reality Labs Research that aims to reconstruct 3D environments and represent the layout of physical spaces using natural language descriptions.
Traditional methods that convert raw sensor data into approximate shapes based on predefined rules. However, SceneScript uses machine learning to convert the scene’s 3D geometry into interpretable text.
Training Approach
Inspired by large language models that use next-token prediction, SceneScript is trained to predict sequences of “architectural tokens” like ‘wall’, ‘door’, etc.
The model ingests a large synthetic dataset of 100,000 scenes with simulated videos during training to learn effectively. It maps visual information into a basic textual representation that describes the layout.
This training paradigm in simulated environments preserved privacy while teaching SceneScript real-world indoor space characteristics at scale. The simulation used sensor characteristics matching Meta’s Project Aria research glasses.
Advantages SceneScript’s text-based scene descriptions offer three key advantages over traditional mesh-based representations:
- Compactness – Reducing memory needs to just a few bytes per scene.
- Crispness – Enabling crisp, scalable vector graphics-like geometry.
- Interpretability – Allowing the representations to be easily read and edited.
Furthermore, SceneScript demonstrates impressive extensibility. By augmenting the training data with additional parameters like door states, the model can predict dynamic scene properties like open/closed doors. Introducing new descriptors enables decomposing objects into primitives like a sofa’s cushions and legs.
To know more more about the project, please visit the official website or read the paper to explore the technicalities.
Google’s MELON
MELON (Modulo Equivalent Latent Optimization of NeRF) is a novel technique introduced by Google Research that tackles the long-standing “chicken-and-egg” problem of reconstructing 3D object geometry from just a few unposed 2D images without any initial camera pose estimates.
The Challenge
Determining camera viewpoints is critical for 3D reconstruction, but is extremely challenging without prior knowledge, especially for objects with pseudo-symmetries that look similar from different angles. This makes the problem ill-posed, causing naive approaches to convergence issues and local minima. For example, the self-similarity map below shows how a toy truck model looks nearly identical every 90° rotation.
The Challenge of Pseudo-Symmetries
As the diagram above illustrates, such pseudo-symmetries make the problem significantly more complex when considering additional degrees of rotational freedom.
MELON’s Approach MELON uses two key innovations to overcome these challenges:
- Dynamic Camera Pose Estimation
Instead of relying on initial pose estimates, MELON employs a lightweight convolutional neural network (CNN) to dynamically predict the camera pose for each input training image during NeRF optimization. This small network capacity acts as an implicit regularizer, forcing visually similar images to map to similar poses. - Modulo Loss Function To account for pseudo-symmetries, MELON renders the object from a fixed set of N viewpoints per input image during training. The photometric loss is backpropagated only through the rendered view that best matches the target image under an L2 distance metric.
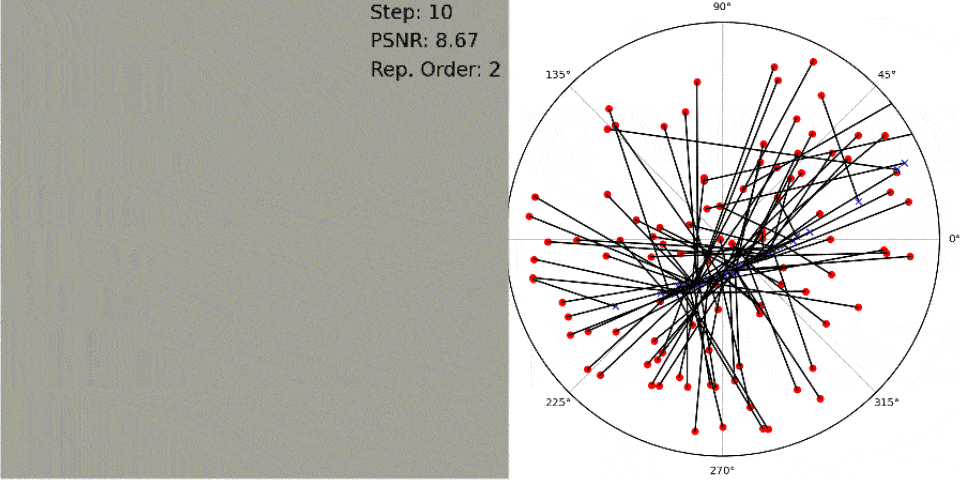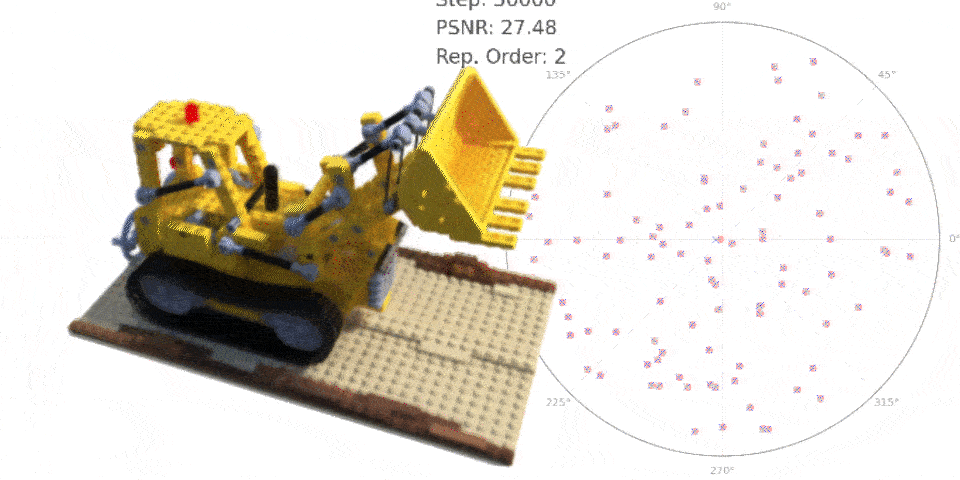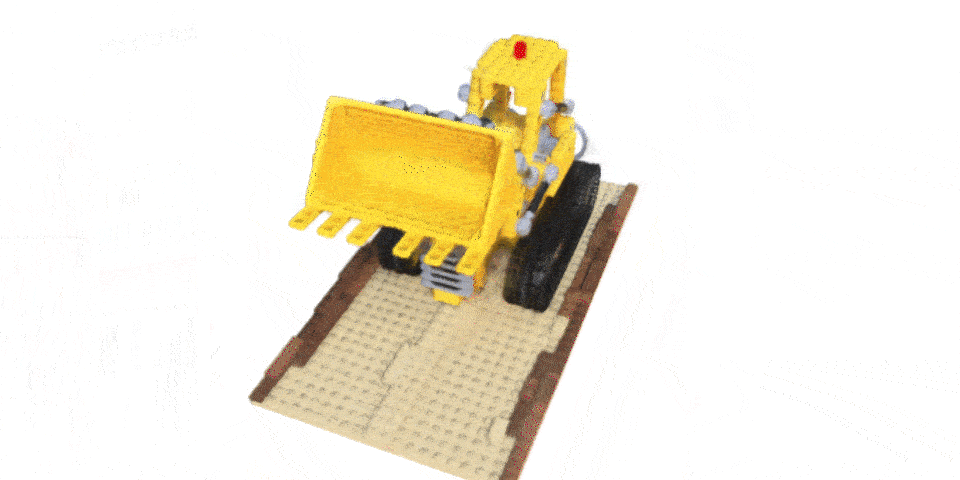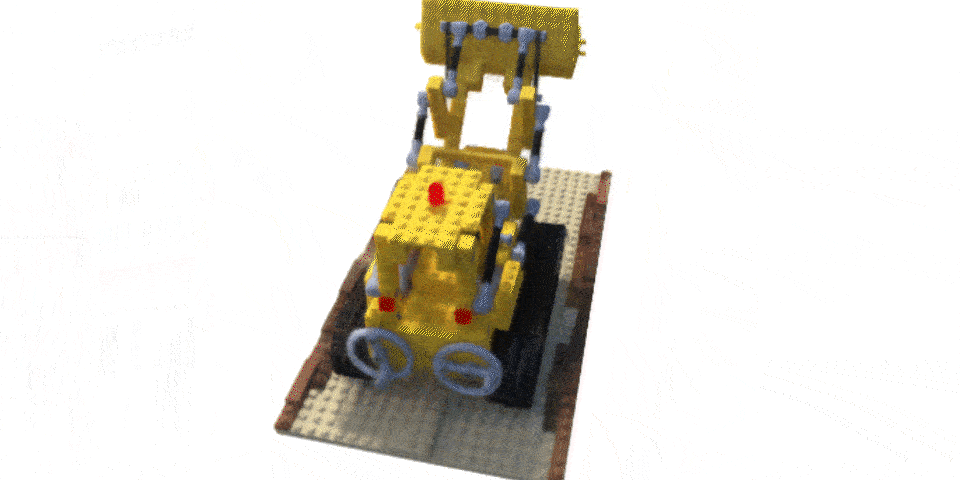
Typically N=2 opposite views are sufficient, but N=4 can improve results for objects with square/cubic symmetries. This modulo loss allows considering multiple plausible viewpoints simultaneously.
By combining these two techniques with standard NeRF volumetric rendering and optimization, MELON achieves state-of-the-art performance on the NeRF Synthetic dataset without any labeled pose data or pretraining.
Key Results
- Accurate pose estimation from as few as 4-6 unposed images per object
- Robust to extremely high noise levels (e.g. σ=1.0 Gaussian noise)
- Can generalize to real-world images beyond synthetic data
While demonstrated on the synthetic NeRF dataset, Google aims to extend MELON to real-world images for applications like e-commerce modeling, robotics, and autonomous navigation systems that require reconstructing 3D environments and objects from limited sensor data.
You can read more about the project here and the paper can be found here.
Stability AI’s Stable Video 3D
Stable Video 3D is a groundbreaking generative model released by Stability AI that builds upon their Stable Video Diffusion foundation to enable high-quality novel view synthesis and 3D generation directly from just single 2D image inputs.
Model Variants The release includes two main model variants:
- SV3D_u This unconditional variant generates orbital video renderings of 3D objects from only a single still image input, without any camera path conditioning.
- SV3D_p The conditional SV3D_p extends the capabilities further by accepting both single images as well as existing multi-view image/video inputs along with associated camera paths. This allows generating controlled 3D video renderings along specified trajectories.
Advantages of Video Diffusion Models
By adapting their previous Stable Video Diffusion model, which converts input images to video outputs, Stable Video 3D leverages the key benefits that video diffusion architectures provide compared to standard image diffusion models like their Stable Zero123:
- Improved Multi-View Consistency
- Better Generalization to Unseen Viewpoints
These properties are vital for synthesizing coherent novel viewpoints of 3D objects and scenes.
Novel View Synthesis Innovations
Stable Video 3D introduces new architectural innovations that significantly advance the state-of-the-art for novel view synthesis (NVS) tasks:
- Camera Path Conditioning (SV3D_p) By conditioning on input camera parameters, SV3D_p can generate consistent video renderings along controlled trajectories.
- Arbitrary Orbit Generation (SV3D_u) The unconditional SV3D_u can automatically synthesize multi-view “orbital” videos encircling objects from just single image inputs.
This enhances both view-controllability as well as ensuring visual consistency when rendering objects from previously unseen angles – a major challenge for prior NVS approaches.
Read more about the project here.
3D Reconstruction Pipeline
In addition to just synthesizing novel views, Stable Video 3D introduces innovative techniques to leverage its strong multi-view consistency for high-fidelity 3D reconstruction:
- NeRF and Mesh Optimization The generated multi-view videos are used to optimize detailed Neural Radiance Field (NeRF) volumetric representations as well as textured 3D meshes of the input objects.
- Masked Score Distillation Loss A new masked score distillation sampling loss function helps improve 3D reconstruction quality in regions not visible from the predicted viewpoints.
- Disentangled Lighting Optimization To prevent baked-in lighting effects, Stable Video 3D employs a disentangled illumination model optimized jointly with the 3D shape and texture.
Applications and Use Cases
Augmented Reality (AR)
SceneScript’s text-based scene descriptions enable spatially-aware AR experiences. AR glasses could leverage these to dynamically map environments, occlude digital objects behind real surfaces, and provide comprehensible scene context to virtual assistants. For example, AR directions could describe “go through the door to your left” using the inferred geometry.
SceneScript can also decompose objects into primitives like a sofa’s cushions and legs. This granular geometry allows realistic occlusion and physics interactions between AR objects and real environments.
Virtual Reality (VR)
Stable Video 3D’s multi-view consistency and high-fidelity mesh outputs are ideal for photorealistic virtualized 3D spaces and digital twins. Combining 360 photography input with Stable Video 3D’s conditional generation enables recreating entire rooms or facilities with moving viewpoints.
This enables VR use cases like virtualized real estate tours, architectural visualization, and training environments matched to existing spaces.
3D Asset Creation
Stable Video 3D and MELON greatly accelerate transforming 2D images or videos into high-quality 3D assets for games, films, and product visualization.
Game developers can capture real-world object turntables with a smartphone, then directly generate textured 3D meshes optimized for real-time rendering. MELON demonstrated reconstructing 3D models from as few as 4-6 unposed images.
For visual effects, MELON enables digitizing props and sets from limited camera angles, aiding environment modeling. Stable Video 3D excels at digitizing human performances and detailed object scans.
Robotic Perception
MELON’s ability to map environments from a few images makes it ideal for spatial understanding on mobile robots or autonomous vehicles. Inferring the geometry allows path planning, obstacle avoidance, and manipulating objects.
As an example, a warehouse robot could use MELON to quickly reconstruct its surroundings, enabling navigation and identifying storage bins or objects to interact with.
3D Visualization
E-commerce platforms can leverage generated 3D assets to provide interactive product viewers, improving online shopping experiences.
Social apps and communication tools can integrate 3D reconstruction to enable immersive avatar customization and shared virtual spaces.

Newsletter