Open-Source Latte Released: Train Your Own SORA-like Text-to-Video
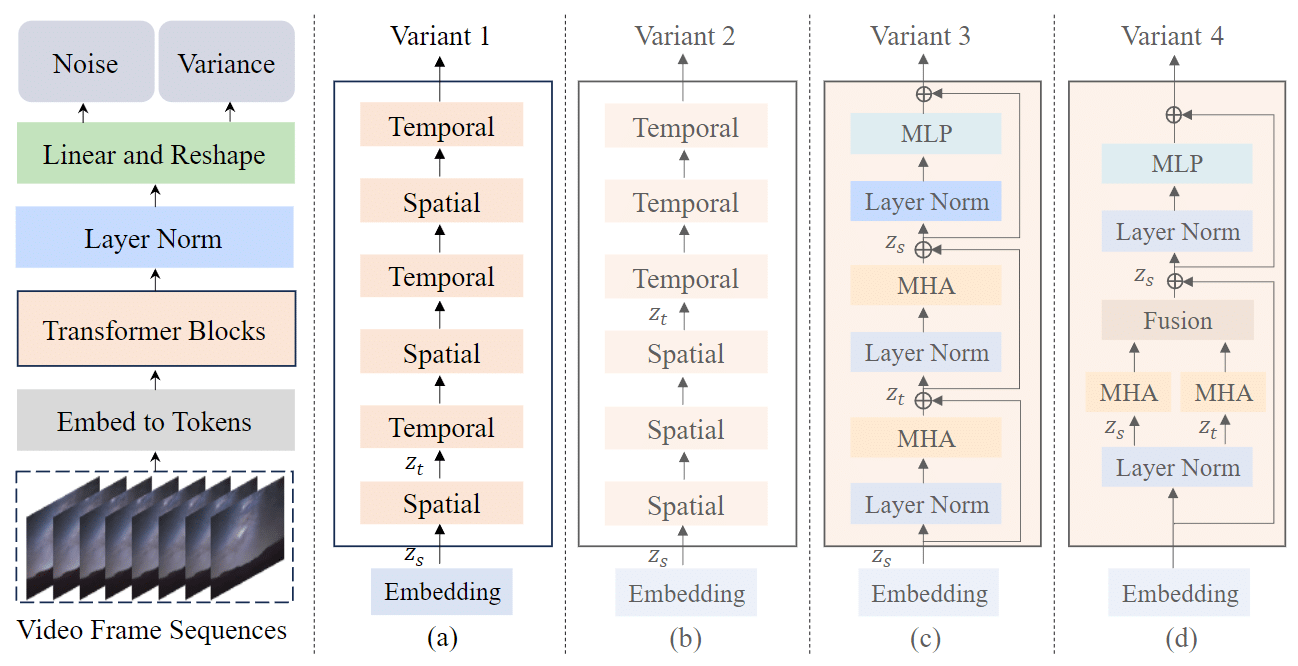
Figure. 1: Latte's Architecture

Newsletter
Get Every Weekly Update & Insights
[mc4wp_form id=]
Back To Top
Figure. 1: Latte's Architecture
Newsletter