Navigating Complex Data Landscapes with TaskWeaver's Innovative Framework
Microsoft introduces TaskWeaver, a revolutionary code-first agent framework designed to revolutionize data analytics and domain adaptation. Moreover, this new tool integrates user requests into executable code, leveraging the capabilities of Large Language Models (LLMs) to process and understand natural language effectively.
Furthermore, TaskWeaver stands out for its ability to handle user-defined plugins as callable functions, offering customization and flexibility in data analysis. It aims to simplify the interaction between data structures and analytics processes, making it a practical choice for analysts and developers.
A New Era in Data Analytics
The release of TaskWeaver is a step forward in data analytics. It’s built to manage data tasks efficiently and securely, ensuring that users can navigate through data and make informed decisions with ease. In this article, we will explore the features, capabilities, and structure of TaskWeaver, demonstrating how it fits into the current landscape of data analytics.
1. What is TaskWeaver?
Microsoft Research presents TaskWeaver, a groundbreaking framework designed to transform user queries into executable code for data analytics tasks. It utilizes Large Language Models to process and respond to these queries in a way that’s actionable for data processing.
Furthermore, the framework is organized into three main components: the Planner, the Code Interpreter, and Memory, as illustrated in figure 1. The Planner receives the initial user query, consults with the LLM, and formulates a plan that includes sub-tasks. These sub-tasks are then handed off to the Code Interpreter.
1.1 TaskWeaver Architecture
Additionally, the Code Interpreter comprises two sub-components: the Code Generator and the Stateful Code Executor. The Code Generator takes the Planner’s sub-tasks and crafts Python code, using plugins and examples as its resources. It reflects on its actions, improving its responses over time. The Stateful Code Executor then runs the code, maintaining the state across different executions, which is crucial for tasks that require memory of previous interactions or data states.
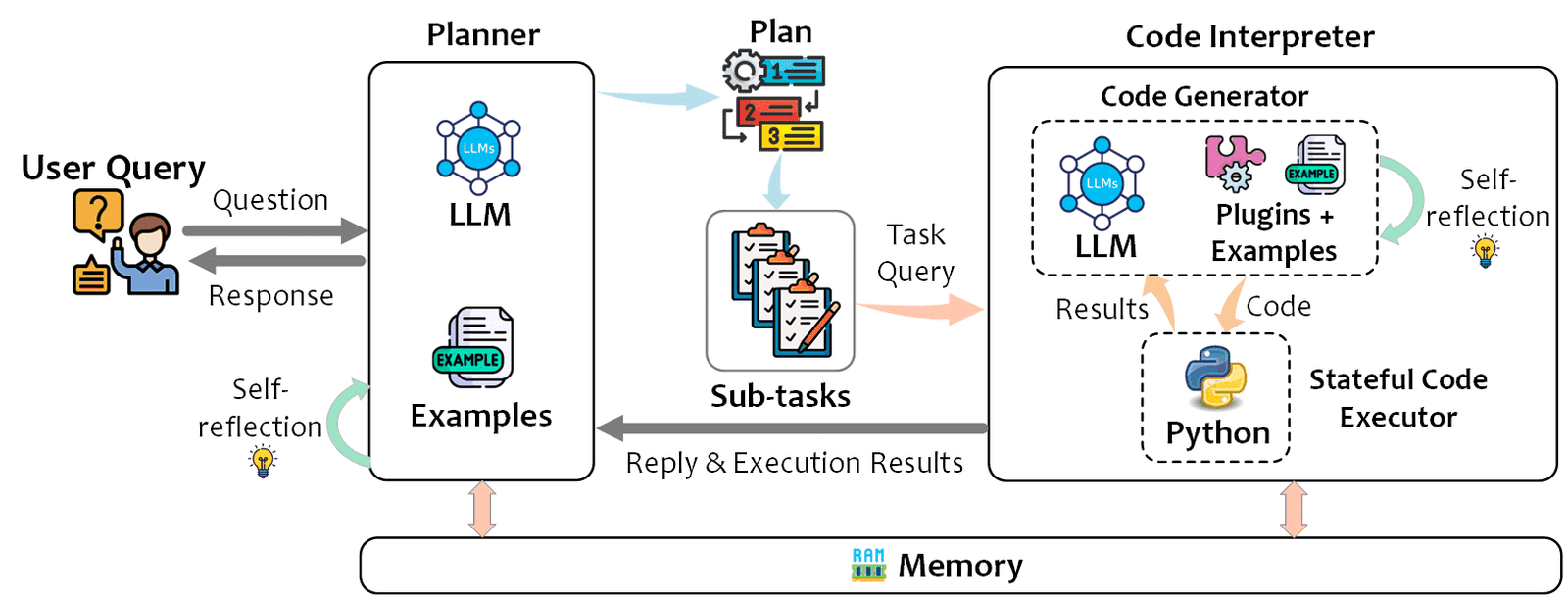
Figure. 1: Overview of TaskWeaver Architecture: Showcasing the flow from user query through the Planner and Code Interpreter, highlighting the self-reflective loop and memory integration.
1.2 TaskWeaver in Action
For instance, consider a scenario where a user needs to pull data from a database and apply anomaly detection. As shown in figure 2, TaskWeaver’s Planner would start by outlining a plan to retrieve the data and then describe the data schema. Next, the Code Generator would create Python code to execute these steps using predefined plugins, such as sql_pull_data for data retrieval and anomaly_detection for identifying outliers. The Stateful Code Executor would run this code, pull the data, and apply the anomaly detection algorithm.
Subsequently, the execution results are then reported back to the user, completing the cycle. This example demonstrates how TaskWeaver not only automates the code generation process but also intelligently orchestrates the execution of complex data tasks by utilizing its plugins and memory capabilities.
In practical terms, TaskWeaver offers a structured and efficient way to handle sophisticated data operations through an interface that is grounded in code yet accessible through natural language. This balance ensures that users can approach complex data analytics tasks without getting bogged down by the intricacies of coding every single detail.
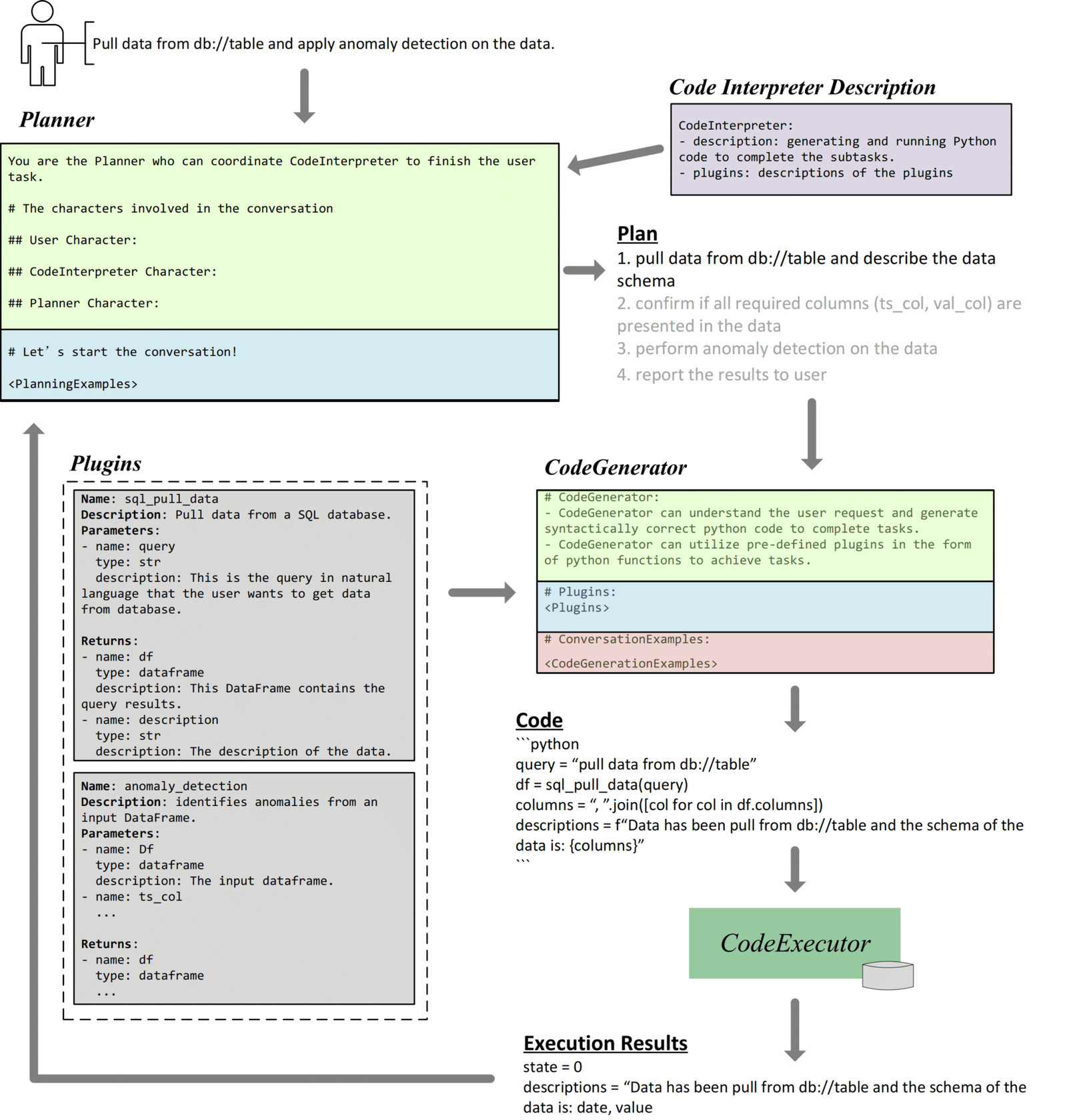
Figure. 2: TaskWeaver in Action: An example of executing a data retrieval and anomaly detection task, detailing the roles of the Planner, Code Generator, and the execution workflow with plugins.
2. Unique Features and Capabilities
TaskWeaver skillfully manages rich data structures and implements complex logic through an advanced system of plugins. These plugins act as Python functions that can be invoked within TaskWeaver to perform specific tasks. For instance, the sql_pull_data plugin can extract data from a SQL database with a command like:
df, data_description = sql_pull_data(query="SELECT * FROM time_series_table")
Following data retrieval, TaskWeaver can employ another plugin, such as anomaly_detection, to analyze the data. The anomaly_detection plugin could be used as follows:
anomaly_df, anomaly_description = anomaly_detection(df, time_col_name="timestamp", value_col_name="value")
This plugin, for example, would add a new column to the DataFrame indicating whether each entry is an anomaly based on a specified logic, such as the 3-sigma rule.
3. Design Considerations
TaskWeaver’s design considerations focus on streamlining the data analytics process for optimal efficiency. The plugins are written in Python and decorated with a TaskWeaver plugin decorator to facilitate their integration into the workflow. The anomaly_detection plugin might look like this in code:
from taskweaver import Plugin, register_plugin
@register_plugin
class AnomalyDetectionPlugin(Plugin):
def __call__(self, df, time_col_name, value_col_name):
# Anomaly detection logic goes here
# ...
return df, "Detected anomalies in the data."
Plugins return a description of their execution results, which is essential for the LLM to understand the outcome of the operation. For example, after performing anomaly detection, the description would be “Detected X number of anomalies in the dataset.”
TaskWeaver’s plugins also come with a YAML schema that outlines their structure. The schema for anomaly_detection might look like:
name: anomaly_detection
enabled: true
description: Identifies anomalies from a DataFrame of time series data.
parameters:
- name: df
type: DataFrame
required: true
description: Input data in DataFrame format.
- name: time_col_name
type: str
required: true
description: Column name for time data.
- name: value_col_name
type: str
required: true
description: Column name for the values to check for anomalies.
returns:
- name: df
type: DataFrame
description: DataFrame with an additional column 'Is_Anomaly'.
- name: description
type: str
description: A summary of the anomaly detection results.
With these design considerations, TaskWeaver ensures that plugins not only perform the required data operations but also communicate their results effectively to the user and the LLM, thus making the analytics process more intuitive and results-oriented.
4. Getting Started with TaskWeaver
Follow these steps to begin using TaskWeaver with OpenAI’s models:
1. Installation:
TaskWeaver can be cloned from its GitHub repository and installed using pip. Run the following commands in your terminal:
git clone https://github.com/microsoft/TaskWeaver.git
cd TaskWeaver
pip install -r requirements.txt
2. Configuration:
Create an account on OpenAI and obtain your API key. Then configure TaskWeaver to use OpenAI by adding the following to your taskweaver_config.json file:
{
"llm.api_type": "openai",
"llm.api_base": "https://api.openai.com/v1",
"llm.api_key": "YOUR_API_KEY",
"llm.model": "gpt-4-1106-preview",
"llm.response_format": "json_object"
}
Replace "YOUR_API_KEY" with the actual API key you obtained from OpenAI.
3. Connecting to Data Source:
If your task involves interacting with a database or other data source, ensure that the necessary connection strings, credentials, and plugins (for example, sql_pull_data) are correctly set up in TaskWeaver.
4. Running TaskWeaver:
With the installation and configuration complete, you can start using TaskWeaver. Here’s an example of how to initiate TaskWeaver with OpenAI’s API in a Python script:
from taskweaver import TaskWeaver
# Replace 'YOUR_API_KEY' with your actual OpenAI API key
tw = TaskWeaver(api_key='YOUR_API_KEY')
# Start a session with TaskWeaver
session = tw.start_session()
# Now you can interact with TaskWeaver using natural language
response = session.query("Analyze the sales trends from the last quarter.")
5. Example Task:
Imagine you’re analyzing last quarter’s sales trends using TaskWeaver. You would start by interacting with TaskWeaver using natural language. TaskWeaver translates your query into a series of sub-tasks, such as pulling data from the sales database and applying statistical analysis to identify trends.
# Assuming 'sql_pull_data' and 'analyze_trends' are predefined plugins
df, description = tw.sql_pull_data("SELECT * FROM sales WHERE date >= '2022-01-01' AND date <= '2022-03-31'")
trends_response = tw.analyze_trends(df, "sales_amount")
print(trends_response)
In addition to integrating with OpenAI’s models, TaskWeaver’s architecture allows for compatibility with a variety of other LLMs and tools. This means that users aren’t limited to a single provider for their language model needs. For instance, you could configure TaskWeaver to work with models from Azure AI or other platforms that offer similar API-driven language services. This flexibility is invaluable for organizations that may require specific features or have existing relationships with different cloud providers.
Furthermore, the extensible plugin system of TaskWeaver is not restricted to data retrieval and analysis tasks alone. It could be extended to integrate with visualization libraries, machine learning models for predictive analytics, or even custom-built tools for domain-specific computations. The potential use cases are vast, ranging from financial forecasting and market analysis to bioinformatics and social media sentiment analysis.
For more details on using TaskWeaver and connecting to various Large Language Models, refer to the official documentation.
5. Extending to Multi-Agent Systems
TaskWeaver’s architecture, inherently flexible and scalable, holds the potential for expansion into a multi-agent system. This transformation would mean moving from a single, centralized agent handling all tasks to a distributed system where multiple agents specialize in different domains or functions and collaborate to achieve complex objectives.
5.1 Potential of Multi-Agent Architecture:
- Specialization: In a multi-agent system, each agent can specialize in a specific domain or function, such as data retrieval, natural language processing, or statistical analysis. This specialization can lead to more efficient and accurate task execution.
Scalability: Distributing tasks across multiple agents can significantly improve the scalability of the system. As the demand for processing power or the complexity of tasks increases, new agents can be added to the system without overburdening existing components.
Resilience: A multi-agent architecture can enhance the resilience of the system. If one agent fails, others can take over its tasks or the system can dynamically reassign the tasks to other agents, ensuring that the system remains operational.
5.2 Benefits of Modularization and Integration:
Modularity:
TaskWeaver’s plugin-based architecture naturally lends itself to modularity. In a multi-agent system, this modularity can be extended further. Agents can be developed, tested, and deployed independently, reducing the complexity of system upgrades and maintenance.
Ease of Adding New Functions:
Integrating new functions into the system becomes a matter of developing and deploying new agents. This ease of integration encourages innovation and rapid adoption of new techniques and technologies.
Collaborative Problem Solving:
Multiple agents can work together to solve complex problems that are beyond the scope of a single agent. For example, one agent could focus on understanding and processing user queries, another on data retrieval, and another on data analysis and visualization. Together, they can provide a comprehensive solution to complex data analytics challenges.
Customization and Personalization:
Multi-agent systems can be customized and personalized to meet the specific needs of different users or tasks. Agents can be selected and configured based on the requirements of the task at hand, offering a tailored solution for each scenario.
6. Case Studies and Practical Applications
TaskWeaver’s unmatched versatility and robustness render it ideal for a wide array of sectors and scenarios. Here are a few case studies and practical applications that demonstrate the framework’s capabilities:
6.1 Healthcare Data Analysis Case Study
Objective: To identify trends and anomalies in patient health records to assist in early diagnosis and treatment planning.
Implementation:
- Data Retrieval: TaskWeaver pulls patient records from hospital databases using a custom
health_data_retrievalplugin. - Data Analysis: It then analyzes the data for abnormal patterns using a
health_anomaly_detectionplugin, identifying patients who may require further medical attention. - Results: The analysis helps healthcare professionals in early diagnosis and intervention, potentially improving patient outcomes.
6.2 Financial Market Analysis Case Study
Objective: To forecast stock market trends for investment firms to make informed decisions.
Implementation:
- Data Retrieval: TaskWeaver fetches historical stock data from financial APIs using a
financial_data_retrievalplugin. - Trend Analysis: It applies time-series analysis and prediction models, possibly using an
arima_forecastingplugin, to forecast future stock prices. - Results: Investment firms use these insights to develop their investment strategies, potentially leading to more profitable outcomes.
6.3 Social Media Sentiment Analysis Case Study
Objective: To gauge public sentiment on social media platforms about recent product launches for marketing strategy adjustments.
Implementation:
- Data Retrieval: TaskWeaver collects social media posts and comments using a
social_media_data_retrievalplugin. - Sentiment Analysis: It analyzes the sentiment of the collected data using a
sentiment_analysisplugin, categorizing the sentiment as positive, negative, or neutral. - Results: The marketing team uses this analysis to understand public perception, refine marketing strategies, and improve customer engagement.
6.4 Supply Chain Optimization Case Study
Objective: To optimize the supply chain by predicting demand and managing inventory levels efficiently.
Implementation:
- Data Retrieval: TaskWeaver gathers sales and inventory data from multiple sources using a
supply_chain_data_retrievalplugin. - Demand Forecasting: It forecasts product demand using a
demand_forecastingplugin, helping in inventory planning and distribution. - Results: The supply chain team uses these forecasts to manage inventory levels, reducing stockouts and overstock situations, and ultimately saving costs.
These case studies illustrate TaskWeaver’s adaptability and effectiveness across different domains. By leveraging its plugin architecture and LLM capabilities, TaskWeaver offers a powerful solution for data-driven decision-making, providing valuable insights and fostering operational efficiency.
Conclusion
TaskWeaver epitomizes a transformative leap in data analytics and domain adaptation, merging the power of Large Language Models with a flexible, code-first framework. Its capability to convert natural language queries into executable code, enhanced by a versatile plugin system, makes it a robust tool for a wide range of industries.
The practicality of TaskWeaver is evident in its diverse applications, from healthcare and finance to marketing and supply chain management. It not only streamlines data analysis but also enables informed decision-making through actionable insights. As organizations continue to rely heavily on data, TaskWeaver’s emphasis on customization, security, and potential for scalability positions it as an essential tool in the evolving landscape of data analytics.

Newsletter