Interactive Data Analytics in Python with Microsoft LIDA

Figure. 1: LIDA Framework's Modular Process for Interactive Data Visualization. This image illustrates the LIDA framework's process, starting with the Summarizer module that interprets datasets into natural language, to the Goal Explorer and Viz Generator that conceptualize and execute data visualizations. Source: https://arxiv.org/pdf/2303.02927.pdf
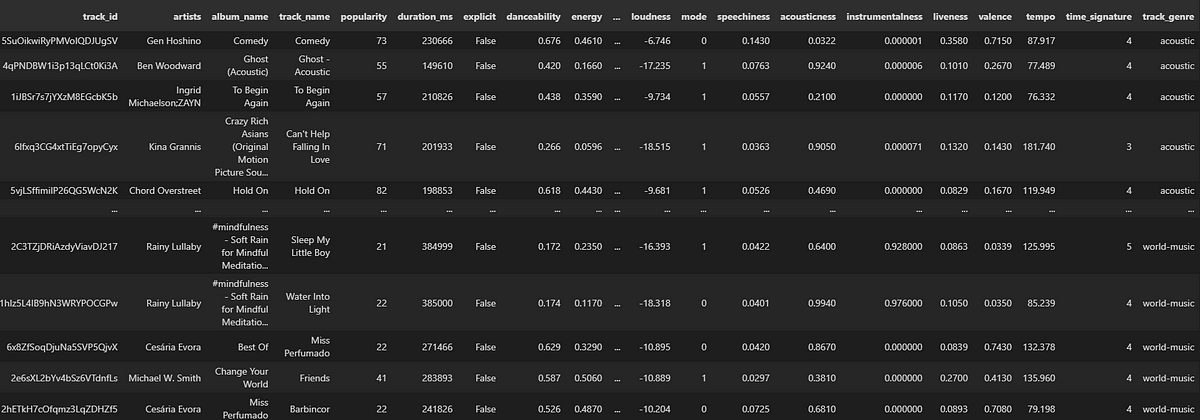
Figure. 2: Excerpt from the Spotify tracks dataset displayed as a pandas DataFrame, illustrating the diversity of data available for analysis, from artists to popularity and track genre.

Figure. 3: An outline of analytical goals generated by LIDA, detailing the interrogation of a music dataset to reveal underlying patterns and relationships.
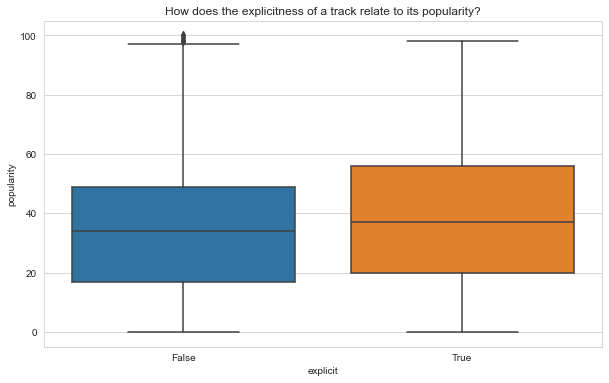
Figure. 4: This box plot, automatically generated by LIDA, visually contrasts the popularity distribution between explicit and non-explicit Spotify tracks, offering a clear perspective on the impact of explicitness on a track's reception.
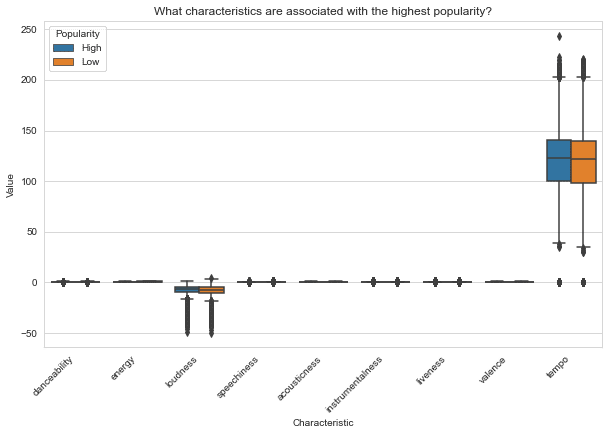
Figure. 5: Box plot visualization automatically generated from a user query in LIDA, comparing the distribution of various musical characteristics against tracks' popularity levels.

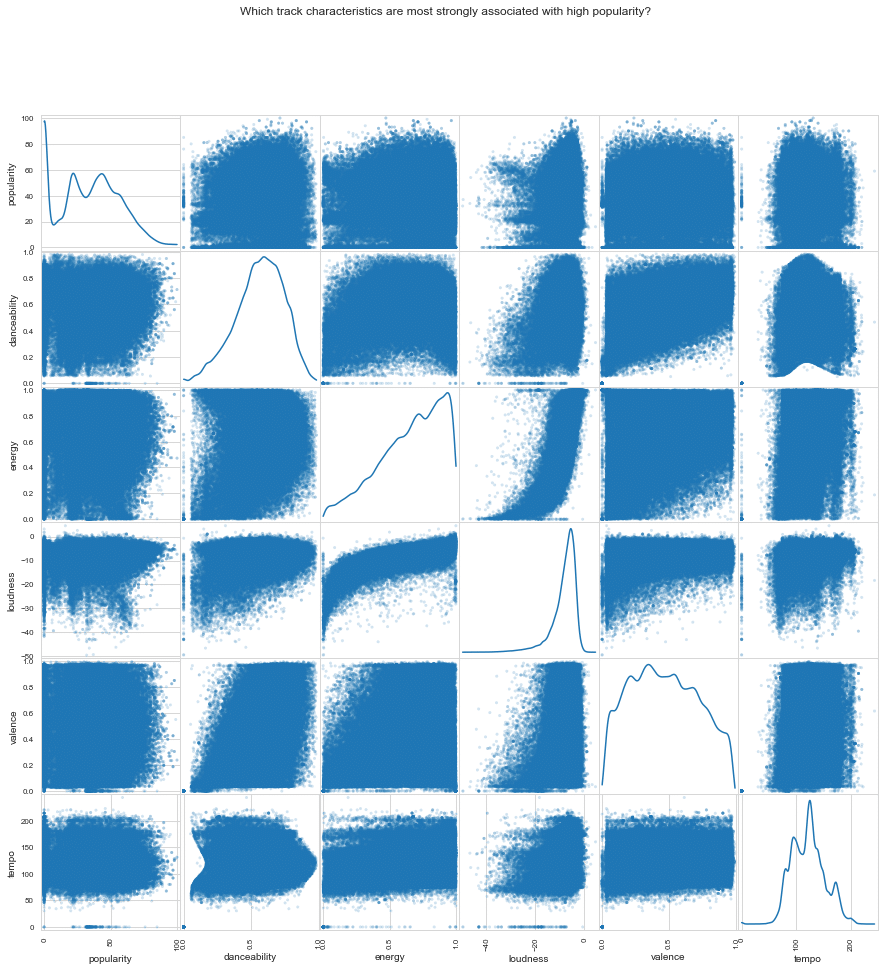
Figure. 6: Scatter plot matrix created using LIDA, revealing the intricate relationships between track popularity and various audio features, as directed by user-defined analytical goals.

Newsletter