Intelligent Web Browsing & Reporting with LangChain and OpenAI
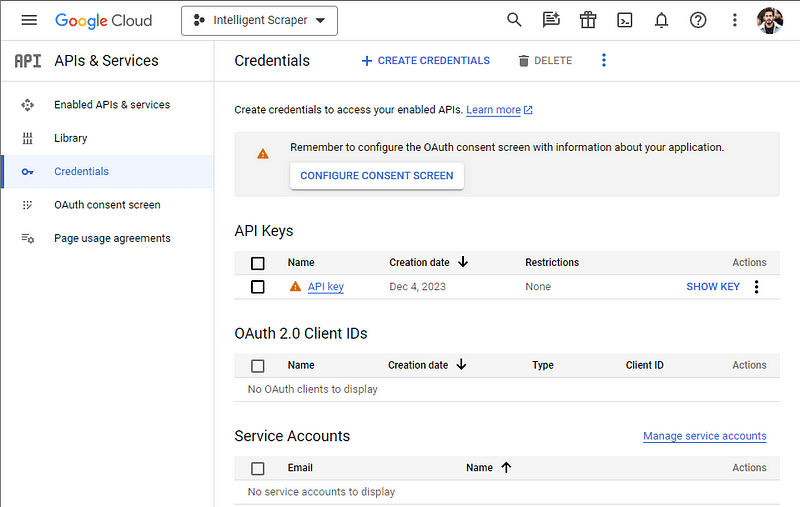
Figure. 1: A Screenshot of the Google Cloud Platform API & Services Credentials dashboard, showing the creation of an API key.
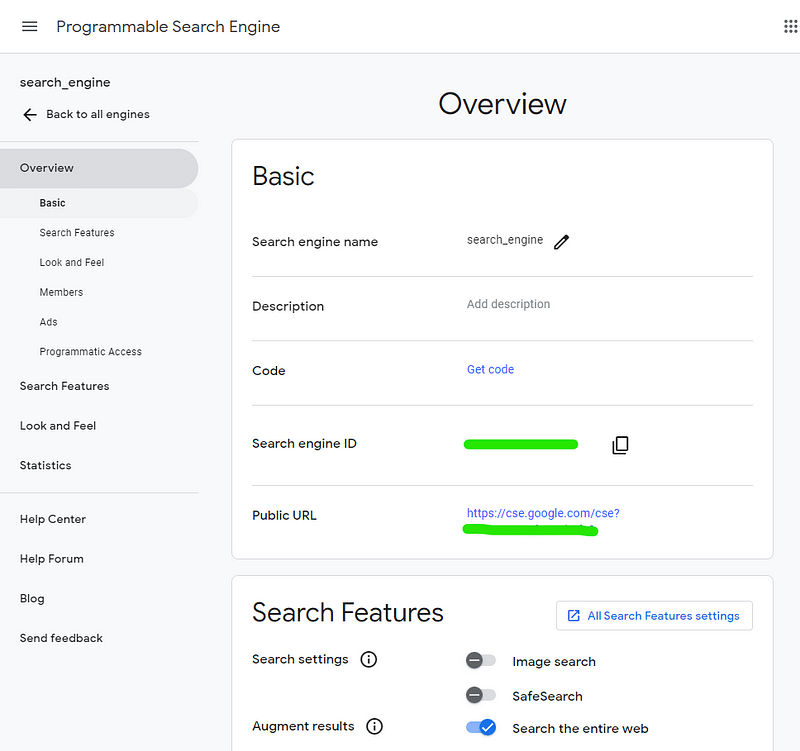
Figure. 2: An interface of Google's Programmable Search Engine management page, showing the basic settings for a user-created search engine including its name, description, and the Search Engine ID.

Figure. 3: An example of an AI-generated response to a financial query, showcasing the main answer regarding the S&P 500 January Effect, followed by a list of sources and summaries providing additional insights and perspectives.

Newsletter
Get Every Weekly Update & Insights
[mc4wp_form id=]