Google Introduces VideoPoet: Multimodal Video Generation
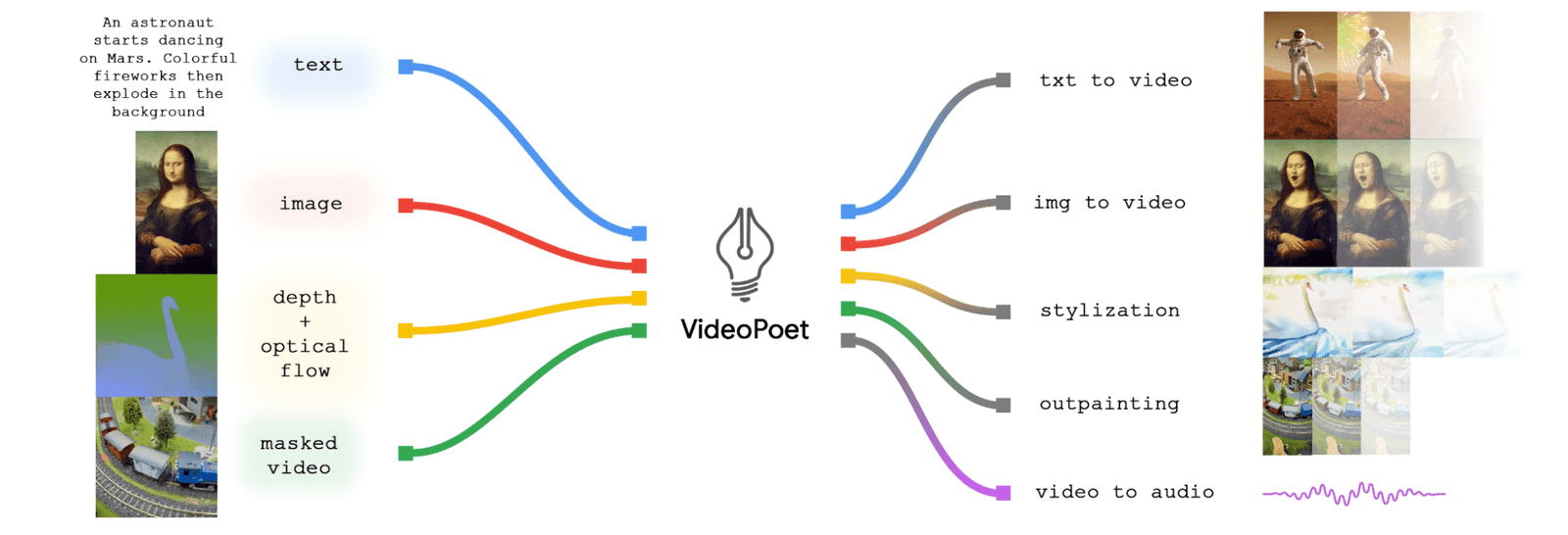
Figure. 1: Illustrating VideoPoet's Multimodal Synthesis Capabilities. (Source: Google Research)

Figure. 2: VideoPoet Architecture: A graphical representation of VideoPoet's bidirectional attention prefix workflow, detailing the process from task tokenization through to the autoregressive generation of video and audio outputs. (Source: Google Research)

Figure. 3: Super-Resolution in VideoPoet: This diagram illustrates the super-resolution module within VideoPoet's architecture, highlighting the multi-axis transformer block's role in enhancing video resolution and detail. (Source: Google Research)

Figure. 4: Sequential Frame Synthesis from VideoPoet: A robotic figure emerges, exhibiting VideoPoet's long video generation capability, where a narrative unfolds over an extended timeline. (Source: Google Research)

Figure. 5: Dynamic Reanimation by VideoPoet: The Mona Lisa's transition from a static painting to a singing animation showcases VideoPoet's image-to-video control feature. (Source: Google Research)

Figure. 6: VideoPoet's Synthesis of Camera Motion: Through a seamless blend of still images, VideoPoet simulates the motion of a camera, adding depth and movement to visual storytelling. (Source: Google Research)

Figure. 7: Human Evaluation Results: A bar chart comparing VideoPoet's text fidelity in video generation against other models, indicating a preference for VideoPoet's accuracy in translating text to video. (Source: Google Research)

Newsletter