Fine-tuning Idefics2 VLM for Document VQA

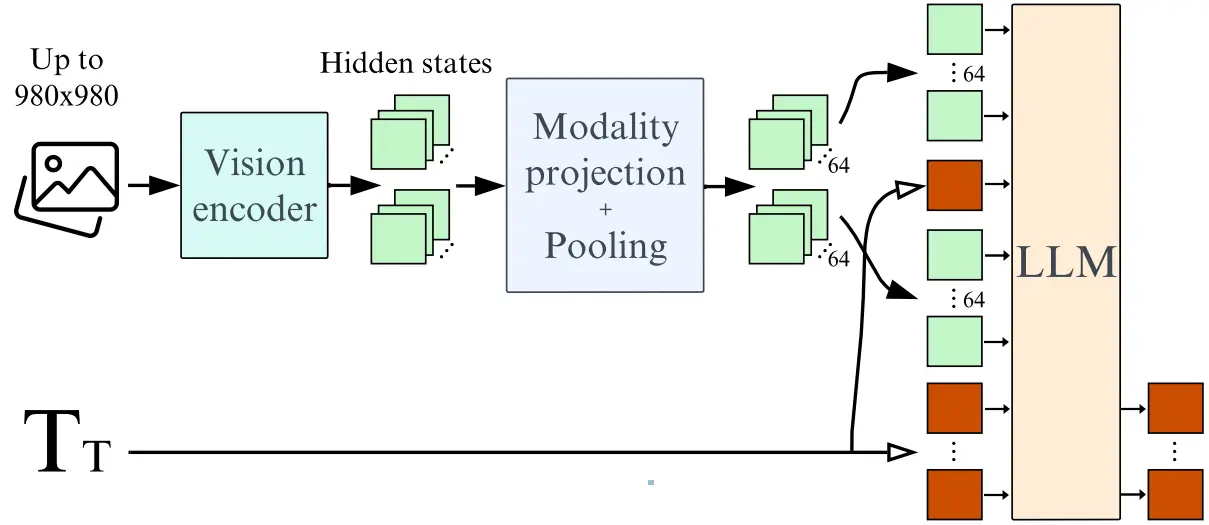
Figure. 1: Idefics2's fully autoregressive architecture processes input images using the vision encoder. The visual features generated are then mapped (and optionally pooled) into the LLM input space to create visual tokens, with 64 tokens being standard. These visual tokens are concatenated (and potentially interleaved) with the text embeddings (shown as green and red columns). This combined sequence is fed into the language model (LLM), which then predicts the output text tokens.

Figure. 2: Idefics2-chatty retrieves the requested information from the resume and arranges it in JSON format.
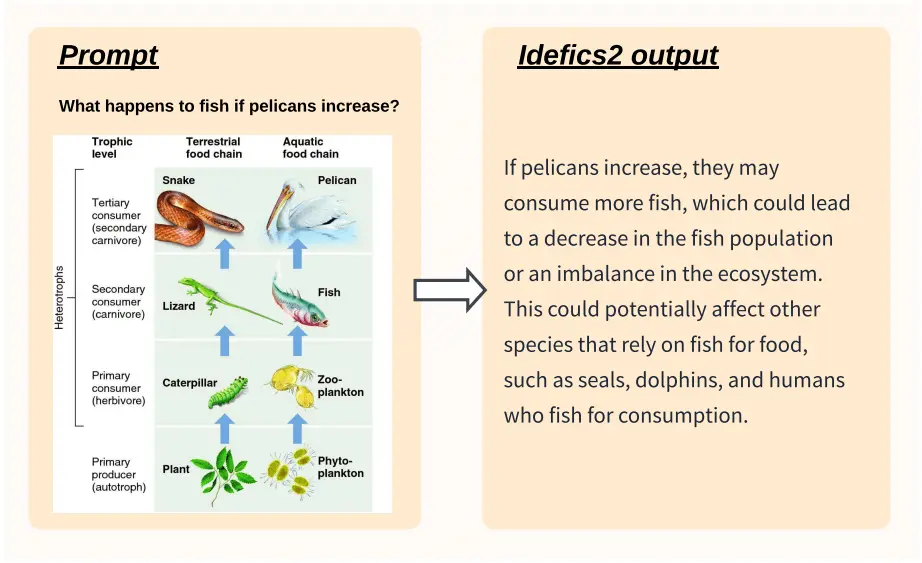
Figure. 3: Idefics2-chatty responds to a question about a scientific diagram.
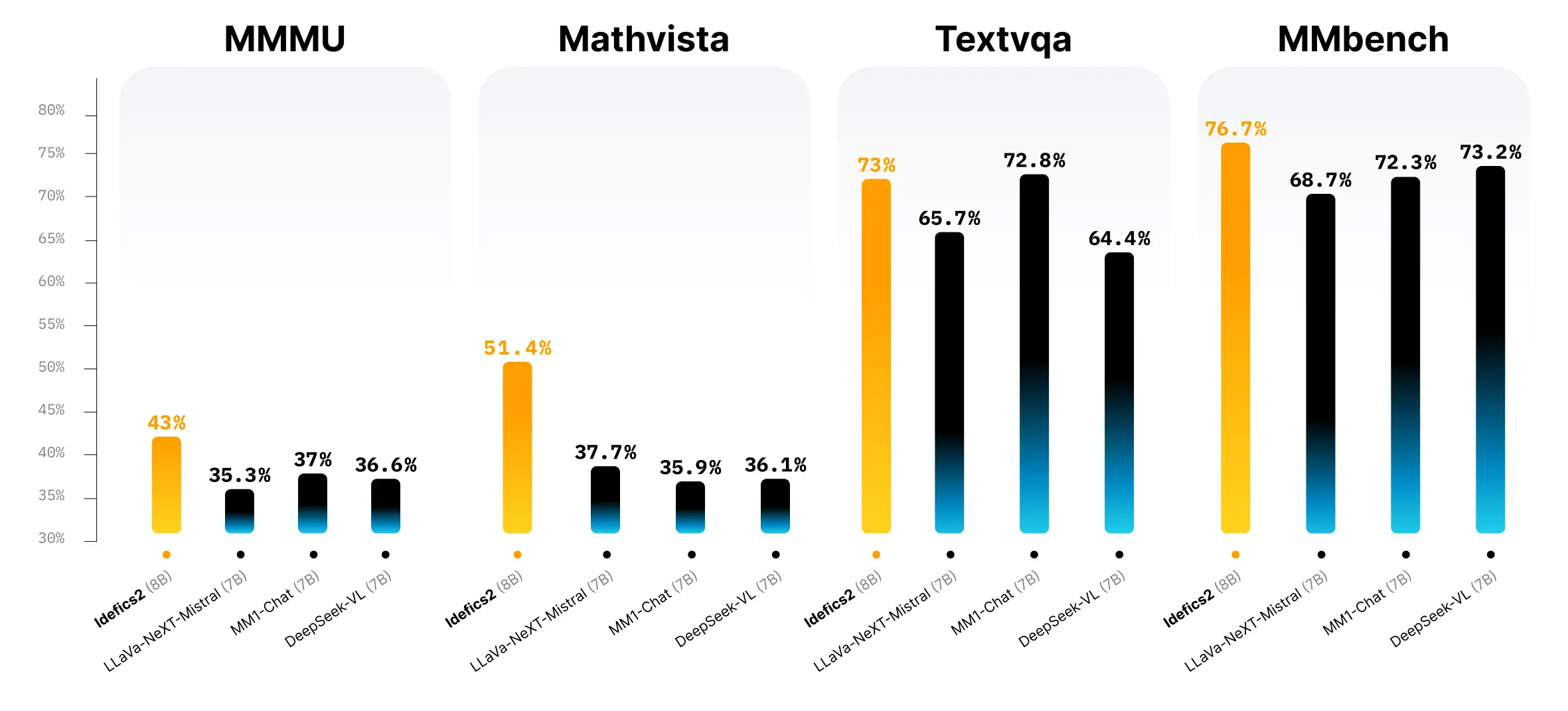
Figure. 4: Performance evaluation of Idefics2 compared to other models across various benchmarks, including MMMU, MathVista, TextVQA, and MMBench.

Figure. 5: Example Document Image in the evaluation dataset.

Newsletter