Automating Scientific Knowledge Retrieval with AI in Python
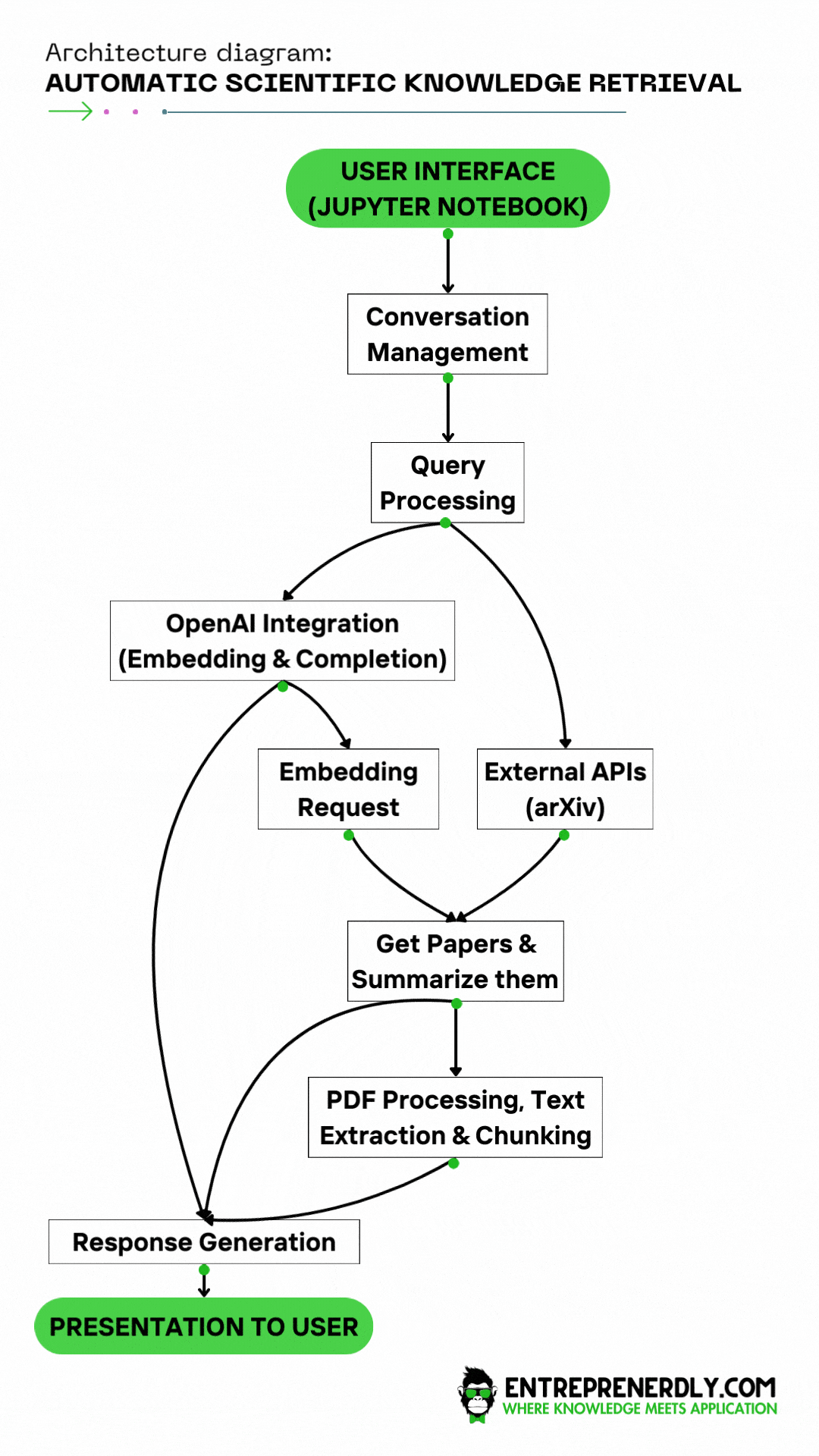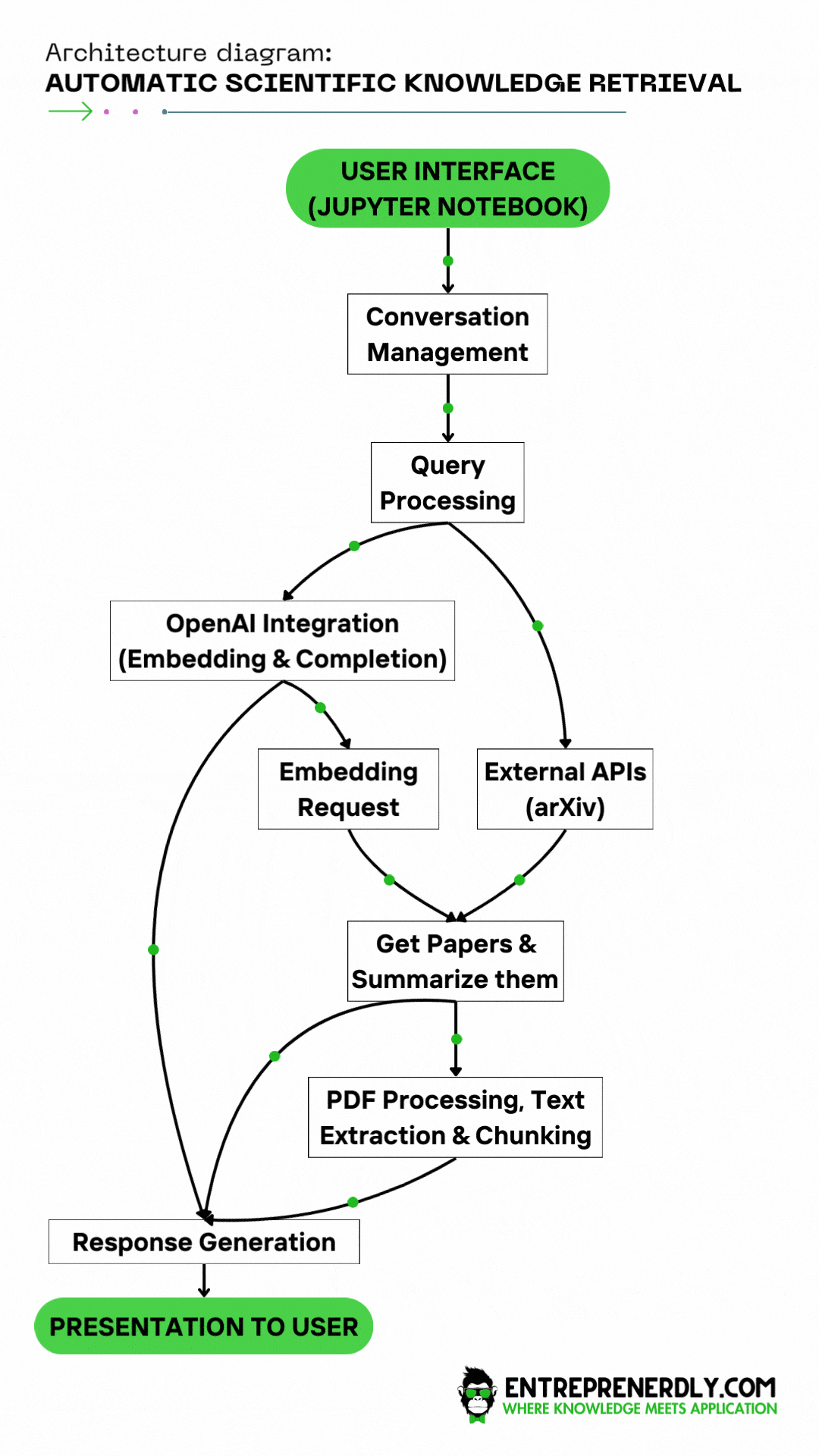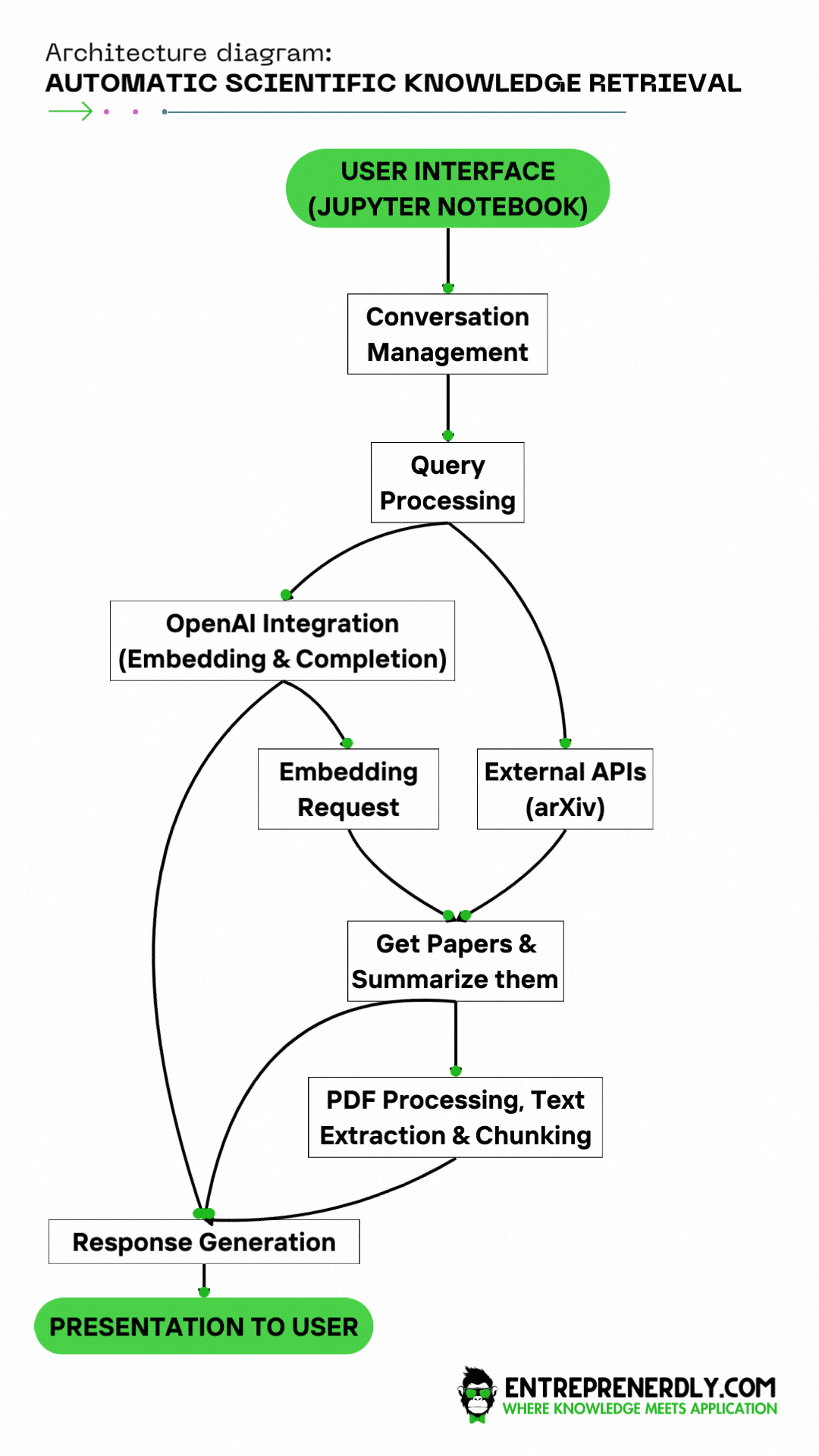
Figure. 1: Solution Architecture for Automatic Scientific Knowledge Retrieval with OpenAI Functions and the arXiv API.

Newsletter
Get Every Weekly Update & Insights
[mc4wp_form id=]