Apple Releases Instruction-Based Image Editing Models Playground

Figure. 1: Gradio app interface on a mobile device, showcasing the image upload feature and submission button ready for live user interaction.

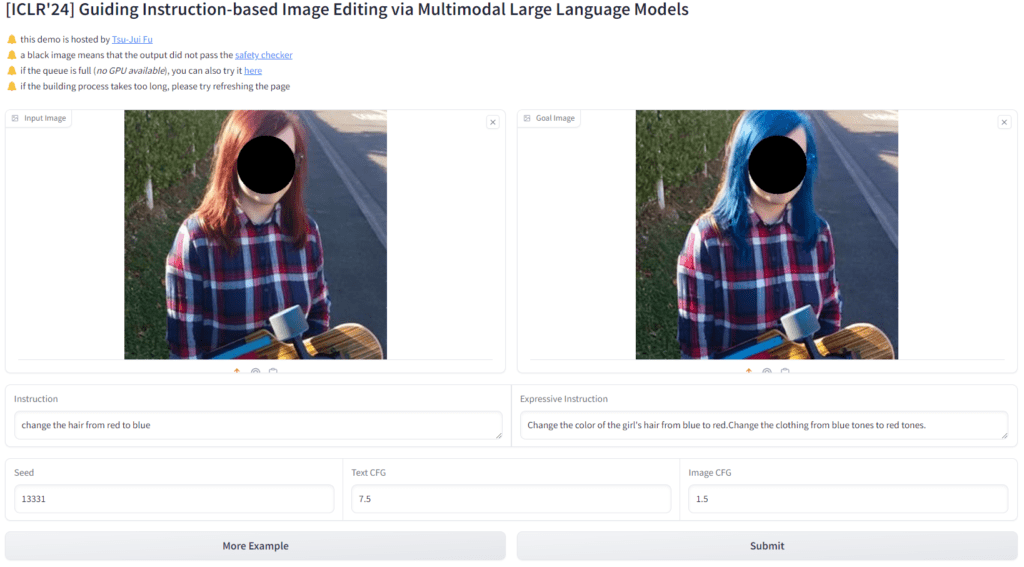

Figure. 4: Overview of MLLM-Guided Image Editing (MGIE), which leverages MLLMs to enhance instruction-based image editing. MGIE learns to derive concise expressive instructions and provides explicit visual-related guidance for the intended goal. The diffusion model jointly trains and achieves image editing with the latent imagination through the edit head in an end-to-end manner. and show the module is trainable and frozen, respectively.

Newsletter
Get Every Weekly Update & Insights
[mc4wp_form id=]