import pandas as pd
import matplotlib.pyplot as plt
#df = pd.DataFrame(data)
#df['Earnings Date'] = pd.to_datetime(df['Earnings Date'])
# Sort the dataframe by 'Earnings Date' in ascending order
latest_earnings_data = earnings_data.sort_values(by='Earnings Date').tail(14)
# Setting up the plot
fig, ax1 = plt.subplots(figsize=(30,8))
# Bar positions
positions = range(len(latest_earnings_data ))
width = 0.25
r1 = [pos - width for pos in positions]
r2 = positions
r3 = [pos + width for pos in positions]
# Clustered bar plots for prices
bars1 = ax1.bar(r1, latest_earnings_data ['Price Before'], width=width, label='Price Before', color='blue', edgecolor='grey')
bars2 = ax1.bar(r2, latest_earnings_data ['Price On'], width=width, label='Price On', color='cyan', edgecolor='grey')
bars3 = ax1.bar(r3, latest_earnings_data ['Price After'], width=width, label='Price After', color='lightblue', edgecolor='grey')
# Line plots for Surprise(%) and Price Effect (%)
ax2 = ax1.twinx()
ax2.plot(positions, latest_earnings_data ['Surprise(%)'], color='red', marker='o', label='Surprise(%)')
ax2.plot(positions, latest_earnings_data ['Price Effect (%)'], color='green', marker='o', label='Price Effect (%)')
# Annotations for the Surprise(%) and Price Effect (%)
for i, (date, surprise, effect) in enumerate(zip(latest_earnings_data ['Earnings Date'], latest_earnings_data ['Surprise(%)'], latest_earnings_data ['Price Effect (%)'])):
ax2.annotate(f"{surprise}%", (i, surprise), textcoords="offset points", xytext=(0,10), ha='center', fontsize=16, color='red', fontweight='bold')
ax2.annotate(f"{effect:.2f}%", (i, effect), textcoords="offset points", xytext=(0,10), ha='center', fontsize=16, color='green', fontweight='bold')
# Annotations for prices
def annotate_bars(bars, ax):
for bar in bars:
yval = bar.get_height()
ax.text(bar.get_x() + bar.get_width()/2, yval, round(yval, 2), ha='center', va='bottom', fontsize=14, rotation=45)
annotate_bars(bars1, ax1)
annotate_bars(bars2, ax1)
annotate_bars(bars3, ax1)
# Setting x-axis with better spacing
ax1.set_xticks(positions)
ax1.set_xticklabels(latest_earnings_data ['Earnings Date'].dt.strftime('%Y-%m-%d'), rotation=45, ha='right', fontsize=14)
# Setting labels and title
ax1.set_xlabel('Earnings Date', fontweight='bold')
ax1.set_ylabel('Price', fontweight='bold')
ax2.set_ylabel('Percentage (%)', fontweight='bold')
ax1.set_title('Earnings Data with Surprise and Price Effect', fontsize=18)
# Add legends
ax1.legend(loc='upper left')
ax2.legend(loc='upper right')
plt.tight_layout()
plt.show()
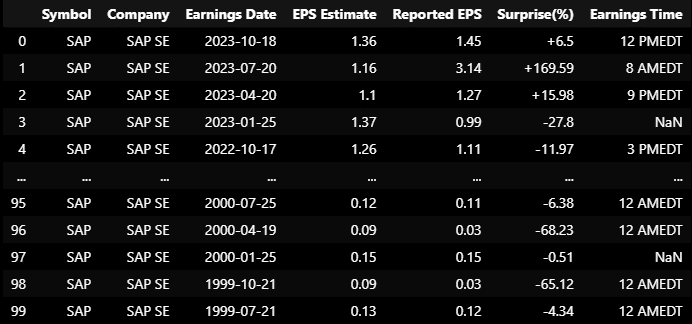

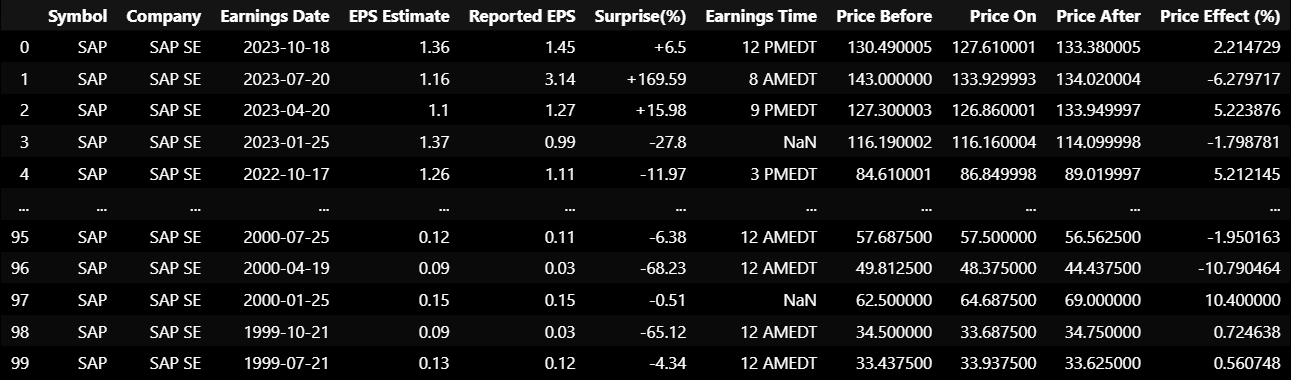

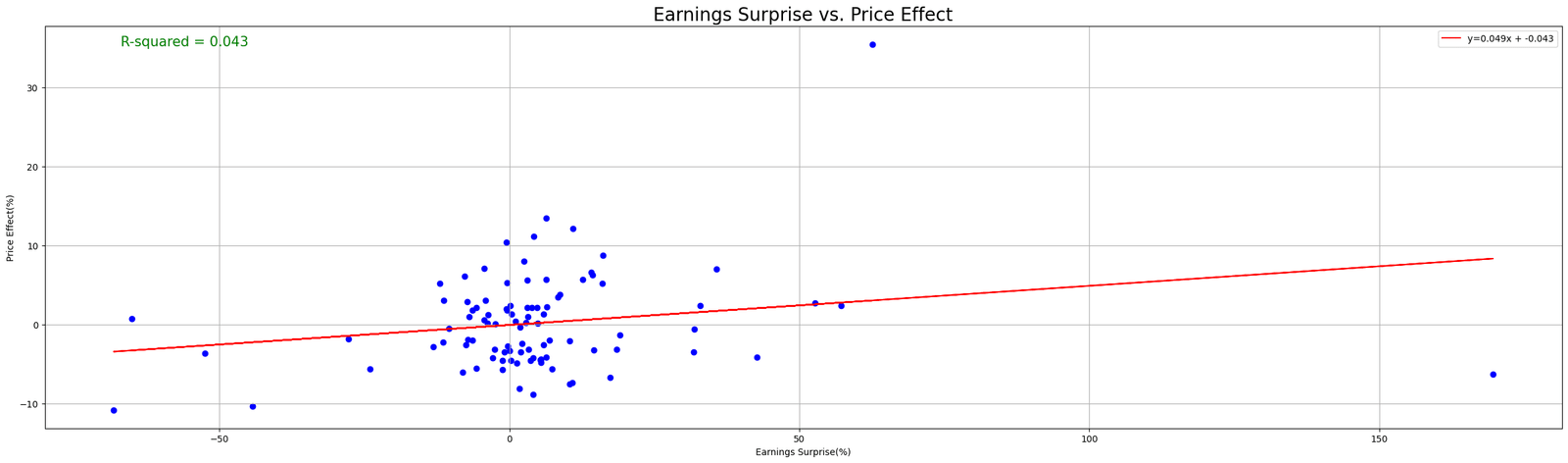

3 thoughts on “Acquiring and Analyzing Earnings Announcements Data in Python”
can u share the code of rthis section
4.2 Market Implied Movemement Probabilities
Moving beyond historical data, we can also utilize market-implied probabilities to gauge expectations about future stock price movements.
This involves analyzing option prices to extract the implied volatility, which reflects the market’s forecast of a stock’s potential to undergo significant price changes. Implied Volatility can be retrieved from the options chain prices on Yahoo Finance.
By applying this market-implied information in Monte Carlo simulations, we can predict a range of potential price outcomes and their associated probabilities for the period around an earnings announcement.
This doesn’t appear to work. Yahoo might have changed the layout of the earnings portal on their website.
Hi Jason,
Indeed—Yahoo Finance has restructured their site, and the earnings announcement data is no longer available.
We’ll look into updating the article with an alternative.
In the meantime, you can access real-time and historical earnings announcement data using our tool:
https://entreprenerdly.com/earnings-announcements-analysis/
Let me know if there’s anything else you need.
Best,
Cristian