Fine-Tuning LayoutLMv2 for Document Question Answering
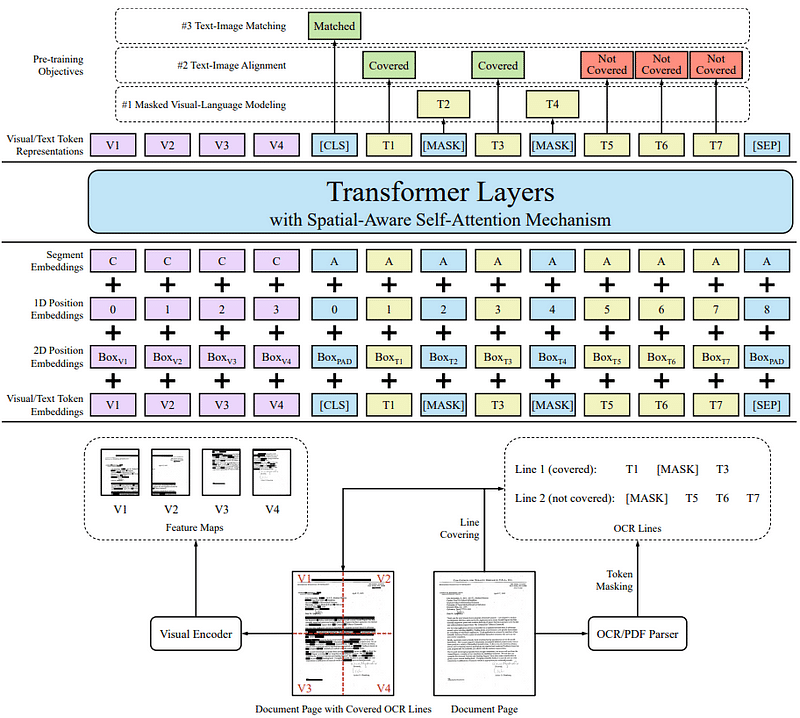
Figure. 1: Diagram of LayoutLMv2 Architecture Illustrating Pre-training Objectives, Input Embeddings, and Transformer Layers with Spatial-Aware Self-Attention Mechanism for Document Understanding and OCR Processing. Source: LayoutLMv2 paper.

Figure. 2: Sample Challenges and Results from the DocVQA Dataset Publication, Showcasing the Comparison of Model Performance (M4C and BERT) Against Ground Truth (GT) and Human Performance in Identifying Text and Numerical Data within Various Document Layouts.

Figure. 3: Example Document in the Training Data.

Newsletter
Get Every Weekly Update & Insights
[mc4wp_form id=]