Earnings Announcements Due Diligence with Groq, Llama 3.1, and LlamaIndex
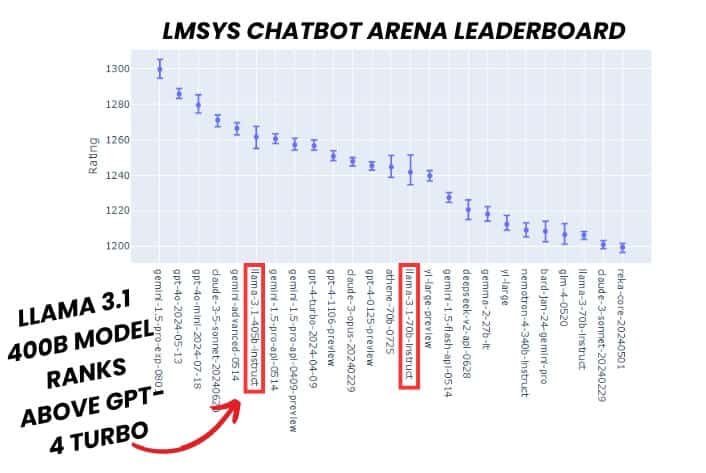
Figure. 1: Huggingface's LMSYS Chatbot Arena Leaderboard. LMSYS Chatbot Arena is a crowdsourced open platform for LLM evals. It collected over 1,000,000 human pairwise comparisons to rank LLMs with the Bradley-Terry model and display the model ratings in Elo-scale. Source: https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
Figure. 2: Groq's AI inference platform overview.
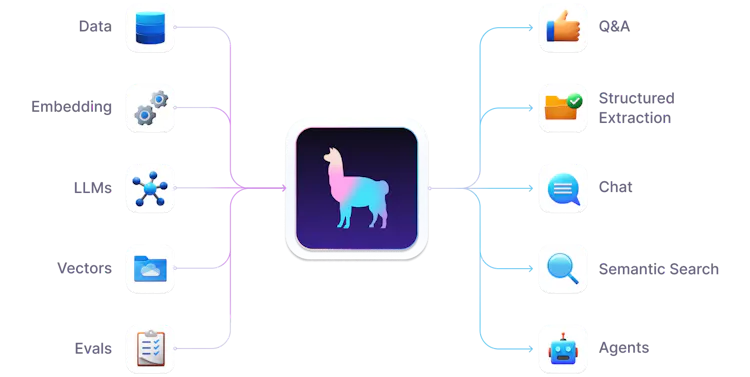
Figure. 3: Diagram of the various components and functionalities of LlamaIndex.

Newsletter
Get Every Weekly Update & Insights
[mc4wp_form id=]