Reconstructing 3D Assets with an Image
3D Reconstructions from a Single Image can transform how we create digital models. Today, anyone can build detailed three-dimensional objects from one photograph. This technology simplifies tasks in various fields such as virtual reality, industrial design, and digital entertainment.
Initially, we set up a proper computational environment at the start of the process. Next, we need to configure the essential models for the task. We then process the image to generate multiple views, which are needed to create the final 3D Reconstructions object.
Furthermore, each step is discussed in relation to the process in detail. We will look at how we prepare the environment, set up models, and convert images into 3D reconstructions from a single image using InstantMesh. Additionally, we provide the end-to-end implementation in Google Colab with the necessary configurations.
This article is structured as follows
- Theoretical Framework of InstantMesh
- End-to-end Python Implementation
- Applications, Challanges and Limitations
1. Theoretical Framework of InstantMesh
1.1 Motivation
InstantMesh addresses the challenge of 3D Reconstructions from a single image, needed for applications like virtual reality and animation. Limited 3D data and poor annotations have historically made this task difficult. Therefore, InstantMesh leverages large-scale diffusion models and a novel architecture to enhance the 3D mesh generation.
1.2 Background and Related Work
Prior works have extended 2D diffusion priors into 3D spaces using methods like score distillation sampling (SDS) and large reconstruction models (LRMs) that map image tokens directly to 3D representations.
1.3 Core Components and Innovations
Multi-View Diffusion Model (MVD). This component synthesizes multiple views from a single image, needed for constructing a 3D model. Moreover, it uses a modified version of the Zero123++ model, optimized to reduce artifacts by maintaining a consistent background across generated images.
Mathematical Formulation of MVD.
The diffusion model uses parameters represented by 𝜃, fine-tuned for consistent background generation, takes 𝐼 as the input image, and synthesizes multi-view images, 𝐼′.
Sparse-View Large Reconstruction Model (LRM). Using a transformer-based architecture capable of handling sparse inputs, LRM transforms the multi-view images into a 3D mesh.
Iso-surface Extraction (FlexiCubes).
𝑀 is the mesh output, 𝑉 represents the volumetric data from LRM, and 𝜙 are the parameters of the FlexiCubes module which apply geometric constraints directly on the mesh.
1.4 Training Strategy and Optimization Techniques
Data Preparation and Training Strategy: Training involves a two-stage approach focusing initially on NeRF representations and transitioning to mesh optimization.
Stage 1: NeRF-Based Training.
This stage focuses on establishing a robust base model using the volumetric rendering capabilities of NeRF. The objective is to learn an initial representation that captures the overall shape and appearance from the synthesized multi-view images.
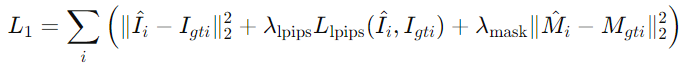
𝐼^𝑖 and 𝑀^𝑖 are the predicted images and masks, 𝐼𝑔𝑡𝑖 and 𝑀𝑔𝑡𝑖 are the ground truth images and masks, and 𝜆 values are the regularization coefficients.
Stage 2: Mesh-Based Optimization.
This stage shifts to a mesh-based approach where FlexiCubes are employed to refine the surface details and improve the mesh’s geometric accuracy. Additionally, in this stage the initial learning from NeRF is leveraged to focus on enhancing surface details and applying realistic textures.

𝐷^𝑖 and 𝑁^𝑖 are the predicted depth maps and normal maps, 𝐷𝑔𝑡𝑖 and 𝑁𝑔𝑡𝑖 are the ground truth values, ⊗ denotes element-wise multiplication, and 𝐿reg is the regularization term for the FlexiCubes.
Camera Augmentation and Perturbation Techniques. Enhancements include random rotations and scaling of camera poses to improve model robustness against varying inputs.
Optimization Techniques.
- AdaLN (Adaptive Layer Normalization): This technique is used within the transformer to adjust the model’s sensitivity to different camera poses, enhancing its ability to generalize across varied viewpoints.
- Regularization and Supervision: Depth and normal supervision are important for refining the model’s output. Moreover, it ensures that the 3D meshes not only visually resemble the input but also adhere to physical dimensions and orientations.
Loss Function Components.
- Depth and Normal Supervision. Enhances the model’s ability to predict accurate geometrical properties by comparing predicted depth maps and normals against their ground truth counterparts.
- Regularization Terms. Include terms for maintaining mesh integrity, preventing overfitting, and encouraging smoothness in the generated meshes.
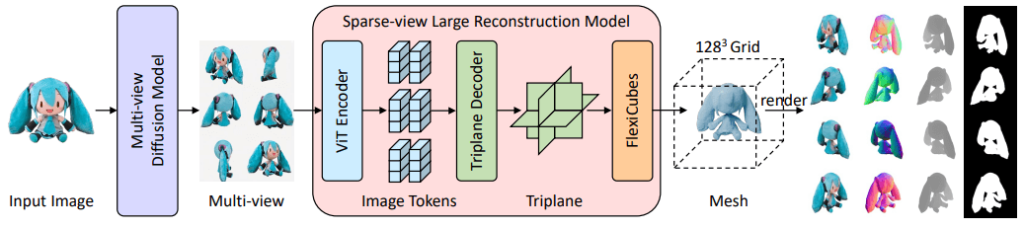
1.5 Workflow Diagram
The diagram below represents the workflow of the InstantMesh framework for generating 3D reconstructions from a single image. Here’s how each component of the diagram contributes to the workflow:
Input Image. With a single input image the process begins, which is depicted in the diagram by an illustrated character.
Multi-view Diffusion Model. Generating multiple views of the input image, this model enhances the spatial understanding necessary for 3D reconstruction. Next, views are shown as several different perspectives of the character, facilitating a comprehensive capture of its 3D structure.
Sparse-view Large Reconstruction Model. Several key components make up this model:
- ViT Encoder. Processing the multi-view images, the Vision Transformer (ViT) encoder converts them into a series of image tokens that encapsulate the essential features from each view.
- Triplane Decoder. This component decodes the image tokens into a triplane representation, a three-dimensional format that serves as an intermediary step before the final mesh generation.
- FlexiCubes. Acting as an iso-surface extraction module, FlexiCubes convert the triplane data into a mesh, applying geometric supervisions directly to refine and detail the 3D output.
128³ Grid. Structured within a 128x128x128 grid, the mesh highlights the resolution and detail captured in the final 3D model.
Rendering. Rendered from various angles, the final mesh showcases the completed 3D model and demonstrates the model’s effectiveness in capturing the comprehensive geometric details of the original input.
1.6 Model Variants and Configuration:
InstantMesh provides several model variants to accommodate various computational needs and application scenarios. These variants fall into categories based on their 3D representation (NeRF vs. Mesh) and parameter scale (base vs. large).
Parameter Configuration for Model Variants:
NeRF and Mesh Variants. The NeRF variants initially use a neural radiance field approach, which excels at capturing intricate volumetric details. On the other hand, the Mesh variants adopt a mesh representation from the start, enabling direct geometric manipulations and often resulting in faster processing times with the FlexiCubes module.
Base and Large Models. The size of the transformer network and the complexity of the triplane or mesh representations primarily distinguish these configurations. Larger models are designed to handle more complex scenes but require more computational resources.
| Model | Representation | Input Views | Transformer Layers | Triplane/Mesh Details |
|--------------|----------------|-------------|------------------------|------------------------|
| InstantNeRF | NeRF | 6 | 12 (Base) / 16 (Large) | Triplane 64x64 |
| InstantMesh | Mesh | 6 | 12 (Base) / 16 (Large) | Mesh grid size 128x128 |
1.7 Experimental Setup and Results
Datasets Used:
- Google Scanned Objects (GSO) and OmniObject3D (Omni3D) are used to validate the model’s performance. These datasets provide a diverse range of objects in varying complexities, which helps in robustly evaluating the model across different scenarios.
- Rendering Settings for Evaluation. Objects are rendered in orbiting trajectories to simulate real-world viewing conditions,. Furthermore, with azimuths and elevations adjusted to capture the object from multiple angles.
Evaluation Metrics:
- 2D Visual Quality Metrics. PSNR, SSIM, and LPIPS assess how closely the rendered views of the generated 3D meshes match the actual photos of the objects.
- 3D Geometric Quality Metrics. Chamfer Distance (CD) and F-Score (FS) are used to measure the accuracy of the 3D shape in comparison to the true object geometry.
Results and Discussion:
- Comparative Analysis. InstantMesh consistently outperforms other baseline models in both 2D visual and 3D geometric metrics. Furthermore, it demonstrates its effectiveness in synthesizing high-quality 3D meshes from single images.
- Model Insights. The experiments highlight the advantages of using a transformer-based approach combined with multi-view consistency and direct geometric supervision. Moreover, the results indicate significant improvements over traditional methods that either rely solely on 2D cues or lack robust multi-view integration.
2. Python Implementation
2.1 Environment Setup
The setup begins by changing the working directory to /content, a standard practice in cloud-based Jupyter notebooks like Google Colab to centralize file operations.
Next, the script clones the ‘InstantMesh’ repository from GitHub. Here, a noteworthy command is GIT_LFS_SKIP_SMUDGE=1. The command prevents Git Large File Storage (LFS) objects from being automatically downloaded during cloning. Moreover, this is particularly useful for saving bandwidth and time, especially when these large files are not required immediately.
Following the repository setup, the script installs specific versions of various Python libraries. Deep learning included are (pytorch-lightning, torchmetrics), user interface creation (gradio), and other utilities (einops, omegaconf).
Additional libraries are installed to handle specialized tasks:
PyMCubesandtrimeshare used for mesh processing.PyMCubesis excellent for extracting isosurfaces (converting 3D voxel data into mesh). Conversely,trimeshis used for easy manipulation and viewing of 3D mesh data.rembg.Used for removing backgrounds from images, crucial for processing where the subject of an image needs to be isolated.nvdiffrastand libraries likejaxandjaxlib.These are essential for differentiable rasterization and numerical computations, enabling complex 3D geometry optimizations that are gradient descent-based.
# Hide outputs
%%capture
# Change the current working directory to "/content" on the system.
%cd /content
# Clone the 'dev' branch of the 'InstantMesh' repository from GitHub.
# GIT_LFS_SKIP_SMUDGE=1 ensures that Git Large File Storage (LFS) objects are not automatically downloaded.
!GIT_LFS_SKIP_SMUDGE=1 git clone -b dev https://github.com/camenduru/InstantMesh
# Change directory to the newly cloned 'InstantMesh' repository.
%cd /content/InstantMesh
# Install specific versions of libraries needed for running InstantMesh.
# This includes libraries for deep learning, data handling, and model acceleration.
!pip install pytorch-lightning==2.1.2 gradio==3.50.2 einops omegaconf torchmetrics webdataset accelerate tensorboard
# Install additional Python libraries that are required for 3D modeling, image processing,
# and deep learning models, such as handling complex 3D object files and performing background removal.
!pip install PyMCubes trimesh rembg transformers diffusers==0.20.2 bitsandbytes imageio[ffmpeg] xatlas plyfile
# Install the nvdiffrast library directly from GitHub for differentiable rasterization of 3D geometries.
# Also install specific versions of JAX and JAXlib for numerical computations and GPU operations,
# along with 'ninja' which is a small build system with a focus on speed.
!pip install git+https://github.com/NVlabs/nvdiffrast jax==0.4.19 jaxlib==0.4.19 ninja
2.2 Model Initialization
Library Loading and Resource Management:
Clearing the GPU cache (torch.cuda.empty_cache()) and resetting any previous model instances (model = None) are key practices to free up memory. Consequently, This ensures that the system resources are optimized before loading new model components, preventing out-of-memory errors.
Model Pipeline Setup:
A
DiffusionPipelineis instantiated from a pre-trained model. This model, identified by"sudo-ai/zero123plus-v1.2", is specifically configured to operate at half precision (torch_dtype=torch.float16). Thus, using half precision is a strategic choice to balance between computational speed and memory usage, making it feasible to run complex models on GPUs with limited memory.The scheduler for the diffusion model is configured with a
trailingtimestep spacing. This configuration affects how the diffusion steps are calculated, optimizing the progression of the noise reduction process during image synthesis. Therefore, although this detail might not be immediately obvious, it is crucial for controlling the quality and stability of the generated images.
Model State Loading:
- Downloading the model’s checkpoint from Hugging Face Hub (
hf_hub_download) and loading it into the model (pipeline.unet.load_state_dict(state_dict, strict=True)) ensures that we have the exact trained parameters ready for deployment. As a result, this step is critical for reproducibility and consistency in model outputs across different platforms and runtime sessions.
Device Configuration:
- Setting the computation device to GPU (
device = torch.device('cuda')) and moving the pipeline to this device (pipeline = pipeline.to(device)) are standard practices for deep learning tasks. Furthermore, they leverage GPU acceleration, significantly speeding up model computations.
Reproducibility:
- A random seed (
seed_everything(0)) guarantees that the model’s outputs are deterministic and reproducible. Moreover, this is particularly important in scientific experiments and product development, where consistent results are necessary.
# Load libraries
import torch
# Empty Cache and clear any previous model references
model = None
torch.cuda.empty_cache()
import numpy as np
import rembg
from PIL import Image
from pytorch_lightning import seed_everything
from einops import rearrange
from diffusers import DiffusionPipeline, EulerAncestralDiscreteScheduler
from huggingface_hub import hf_hub_download
from src.utils.infer_util import remove_background, resize_foreground
%cd /content/InstantMesh
# Initialize a DiffusionPipeline with a pretrained model specified by its identifier.
# This model uses a custom pipeline setting and operates at half precision (float16) to enhance performance on compatible GPUs.
pipeline = DiffusionPipeline.from_pretrained("sudo-ai/zero123plus-v1.2", custom_pipeline="zero123plus", torch_dtype=torch.float16)
# Configure the pipeline's scheduler, setting the timestep spacing to 'trailing' which affects how steps are calculated in the diffusion process.
pipeline.scheduler = EulerAncestralDiscreteScheduler.from_config(pipeline.scheduler.config, timestep_spacing='trailing')
# Download the model checkpoint from the Hugging Face Hub, specifying the repository and the file name.
unet_ckpt_path = hf_hub_download(repo_id="TencentARC/InstantMesh", filename="diffusion_pytorch_model.bin", repo_type="model")
# Load the state dictionary of the model from the downloaded checkpoint, ensuring it's loaded to CPU memory first.
state_dict = torch.load(unet_ckpt_path, map_location='cpu')
# Load the state dictionary into the UNet model within the pipeline, ensuring strict loading to match all model parameters exactly.
pipeline.unet.load_state_dict(state_dict, strict=True)
# Set the device for model computation to GPU for faster processing if available.
device = torch.device('cuda')
# Move the pipeline to the specified device (GPU).
pipeline = pipeline.to(device)
# Set a seed for random number generation to ensure reproducibility of the results.
seed_everything(0)

Also worth reading:
The Rise Of 3D Reconstruction

Newsletter